你的網站擋住 AI 爬蟲了嗎?很多人開始發現,明明網站有排名、有流量,但在 ChatGPT、Perplexity、Google AI 摘要及 AI 模式裡,卻完全找不到自己的內容。隨著 AI 搜尋快速崛起,過去只要讓 Google 順利索引,就有機會獲得曝光,但現在光是被收錄已經不夠了,所以,一個新的概念開始變得重要:AI Crawlability。
AI Crawlability 是什麼?為什麼你的內容沒有被 AI 採用?
AI Crawlability 中文可理解為「AI 可爬取性」,指的是 AI 系統是否能順利抓取網站內容,並進一步理解與使用,與過去 SEO 在談的 Crawlability 有一點不同。
傳統搜尋裡,通常會關注爬蟲能不能讀取網站、頁面有沒有被索引,而在 AI 搜尋環境下,網站內容則可能被 AI 爬蟲(AI crawler):
- 抓取並建立資料基礎
- 成為語言模型參考內容
- 出現在 AI 回答或摘要中
👉 AI Crawlability = 可爬取 + 可理解 + 可引用
所以即使你的內容已經有排名,如果 AI crawler 根本沒有抓取到你的網站,那就完全沒有機會被 AI 使用。
舉個簡單情境:同樣是「調理機推薦」,兩篇文章都有排名,但其中一個網站限制了 AI crawler 存取,或是內容無法被正確抓取,那這篇內容就不會出現在 AI 的資料來源中。
而在能被抓取的前提下,AI 才會進一步挑選內容。例如兩篇都被抓到的文章,其中一篇內容結構清楚、有比較與重點整理,就更容易被 AI 擷取並引用!
AI 爬蟲(AI crawler)是什麼?有哪些 AI 正在抓你的網站?
AI crawler 是由 AI 公司或 AI 搜尋服務使用的爬蟲,用來抓取網路內容,並建立自己的資料來源。
常見 AI crawler 來源例如:
- Googlebot(同時用於傳統搜尋與 AI Overview 、AI Mode 等功能)
- GPTBot(OpenAI)
- ClaudeBot(Anthropic)
- PerplexityBot
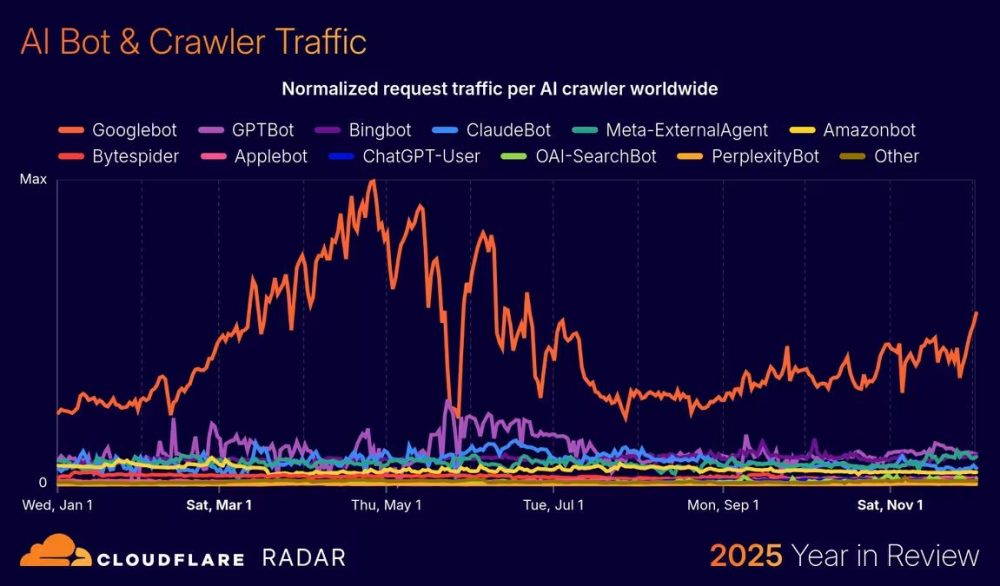
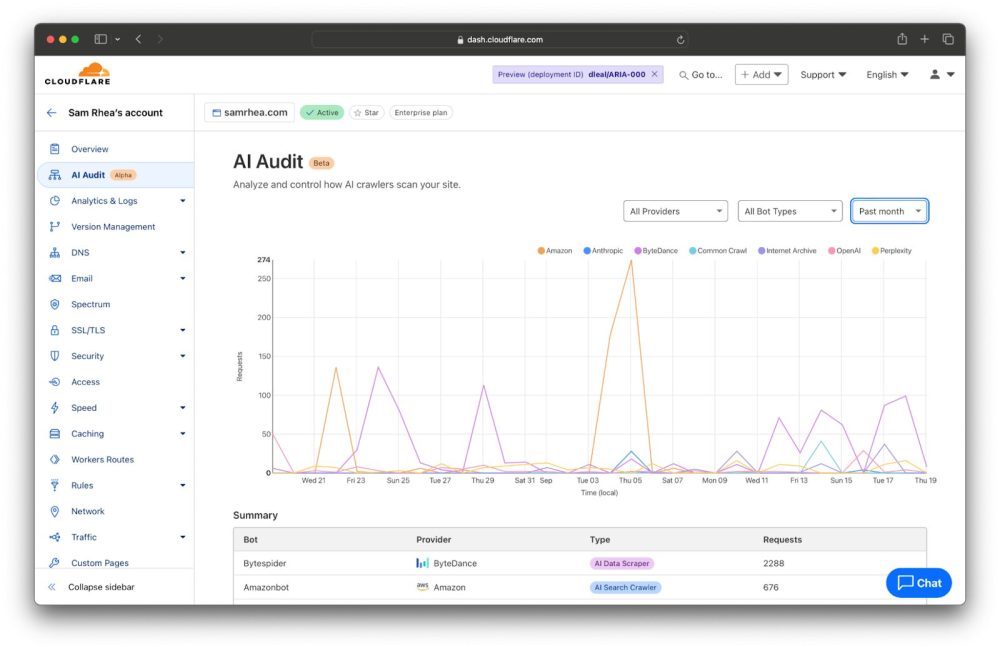
從上圖 Cloudflare Radar 的 2025 年回顧可以觀察到,雖然目前整體仍以 Googlebot 為主,但 AI crawler 已經開始穩定抓取網站內容,搜尋戰場正在從 SERP 擴展到 AI Answer。
AI crawler 在做什麼?為什麼會抓你的內容?
AI 並不像搜尋引擎單純收錄頁面,而是會把內容拿去整理、理解,重新組合再利用。
AI crawler 抓取網站內容通常用於以下目的:
- 建立 AI 搜尋資料來源:像 Perplexity、Google AI Overview,都需要一個資料庫來回答問題。
- 作為語言模型的參考內容:網站內容可能被整理、學習,成為 AI 回答的一部分。
- 用於生成答案或引用來源:當使用者提問時,AI 會選擇合適內容來組合答案,有時也會附上來源連結。
所以其中一個在 SEO 圈很關注的議題:「當 AI 直接在搜尋結果中整理答案時,使用者可能不再點擊原網站,導致零點擊的現象」,對內容提供者來說,大家也會開始思考到底是否應該讓 AI 繼續抓取這些內容?
不過換個角度看,在 AI 搜尋逐漸普及的情況下,若完全抵制 AI 存取內容,也可能同時失去曝光機會。
延伸閱讀:AI 內容會影響 SEO 排名嗎?3 大風險 + AI SEO 真實數據分享!
那我要怎麼知道 AI 有沒有抓我的網站?
目前已經有越來越多工具可以觀察 AI crawler 的行為,甚至能看到誰在抓、引用哪些頁面:
- Cloudflare AI Crawl Control
如果網站使用 Cloudflare,可以直接透過報表辨識 GPTBot、ClaudeBot、PerplexityBot 等 AI 爬蟲,查看請求次數、抓取頻率
- 伺服器 Log 分析
透過 log 檔判斷是否有 AI crawler 的 User-Agent 造訪你的網站
- AI visibility tools(如 Profound、Peec AI)
分析你的品牌或內容是否出現在 AI 回答中(例如 ChatGPT、Perplexity),評估被引用程度
📖延伸閱讀:AI Visibility:網路行銷新時代的關鍵指標
- SEO 工具延伸功能(如 Ahrefs、Semrush 部分功能)
開始提供 AI 引用趨勢觀察(仍在發展中)
AI 爬蟲 vs 搜尋引擎爬蟲:兩種爬蟲的運作邏輯差在哪?
傳統爬蟲在做什麼?
傳統搜尋爬蟲(像 Googlebot)通常會照著固定流程運作,大致可以分成三個階段:
1️⃣ 檢索:發現你的內容
2️⃣ 索引:收錄你的內容
- 解析 HTML,抓取文字與結構
- 建立頁面之間的關聯
- 評估內容品質與相關性
3️⃣ 最後才會進入排名階段
- 根據關鍵字相關性排序
- 評估內容品質、權威性(E-E-A-T)
- 參考使用者體驗與其他排名訊號
AI crawler 多做了哪些事情?
1️⃣ 拆解頁面段落在講什麼
AI 會嘗試理解每一段內容,例如:
- 這段在解釋哪個主題
- 段落之間的關聯
- 是否符合特定搜尋意圖
以前內容是以「頁面」為單位被評估,現在則是以「段落」為單位,單獨被引用
2️⃣ 評估內容是否值得被用
AI 會評估內容品質,例如:
- 資訊是否完整
- 是否有數據或具體說明
- 能不能直接回答使用者的問題
搜尋引擎爬蟲的重點在把頁面收進資料庫;AI crawler 則更偏向在挑出可以用來回答的內容。
搜尋引擎爬蟲 vs AI crawler 差異整理
| 比較項目 | 搜尋引擎爬蟲 | AI crawler |
|---|---|---|
| 爬取目的 | 建立搜尋索引與排名 | 生成回答與引用內容 |
| 爬取頻率 | 高(持續更新索引) | 相對較低(依需求抓取) |
| 爬取範圍 | 偏向全站 | 偏重資訊頁、內容頁 |
| JavaScript 渲染 | 大部分支援 | 多數情境下無法解析 |
| 內容使用方式 | 建立排名訊號 | 直接用於回答 |
為什麼 AI 看不到你的網站?6 大常見 AI Crawlability NG 問題
內容過度依賴 JavaScript
很多現代網站會透過 JavaScript 才載入內容,但 AI crawler 通常只讀最初的 HTML,而雖然近幾年 Google JavaScript 渲染能力上升,看得到完整頁面,但 AI 看到的很有可能仍然是幾乎空白的頁面。
根據 SearchVIU 對 23 個 AI crawler 的分析,約有 69% 的 AI crawler 無法執行 JavaScript,僅能解析原始 HTML,像 GPTBot 雖然會抓取 JavaScript 檔案,但不會真正執行 JavaScript。
內容藏在互動元素裡
有些內容設計對使用者很友善,但對 AI crawler 來說不一定容易理解,例如:
- accordion(手風琴)
- tabs(分頁切換)
- 展開式內容
這些元素通常需要點擊或互動才會顯示完整內容,而 AI crawler 跟傳統搜尋引擎爬蟲一樣,不會操作頁面,將導致部分內容沒有被完整讀取。
延伸閱讀:Tabbed Content是什麼?使用可折疊內容對SEO的影響為何?
robots.txt 設定擋住 AI crawler
有些網站會透過 robots.txt 限制特定爬蟲存取,如果設定不當,AI crawler 也可能被一起擋掉。
例如:
User-agent: GPTBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
以上語法代表 GPTBot、PerplexityBot、ClaudeBot 都無法抓取網站內容,這種設定常見於付費內容平台、獨家資料或不希望被 AI 使用的網站,但若完全擋住 AI 爬蟲也可能會影響曝光。
網站速度太慢
AI 在生成回答時,需要在極短時間內抓取與整理資訊。如果網站載入速度過慢,或伺服器回應不穩定,就可能直接被排除在候選內容之外。
對 AI 來說,抓不到或太慢,通常就會直接換下一個來源。
Infinite Scroll 無限滾動的瀑布流頁面
有些網站採用無限滾動(Infinite Scroll),內容會隨著滑動才逐步載入,與收合元素相同,這種設計對使用者很直覺,但對爬蟲來說,如果沒有額外提供分頁或明確的 URL,可能只會抓到第一段內容。
CDN / 防護機制意外擋掉 AI
有些網站會使用 CDN 或資安防護服務(例如 Cloudflare),來過濾異常流量。但在設定不當的情況下,AI crawler 也可能被當成機器流量直接擋掉。
例如 Cloudflare 在 2025 年 7 月開始提供預設封鎖 AI crawler 的選項,不少網站在未調整設定的情況下,直接從 AI 搜尋結果中消失。
如何提升 AI Crawlability?AI 搜尋可見度優化方法
要讓內容有機會出現在 AI 回答中,可以從兩個面向著手:一是原本 SEO 就需要做好的基礎,二是讓 AI 更容易理解與使用的內容設計。
SEO 基礎:AI 與 Google 都看得懂的網站結構
先從基本功開始,以下基礎 SEO 常見的重點仍然非常重要:
- 清楚的內部連結
讓爬蟲可以順利找到重要頁面,也幫助理解頁面之間的關聯,建立主題集群 Topic Cluster
- 明確的內容架構(H 標籤)
有層次的標題結構,比起一整段長文,用 H2、H3 拆出優缺點、適用族群,更容易被 AI 擷取
- XML Sitemap + robots.txt 設定
確保該被抓的頁面能被存取,不該抓的能被控制
- 避免重複內容、維持清楚 URL 結構
減少判讀混亂,也有助於建立內容主題一致性
- HTML 可直接讀取內容(避免過度依賴 JS)
如果內容需要渲染才能看到,部分 crawler 可能抓不到完整資訊
- 導覽層級控制在 3 層以內
重要內容不要藏太深,避免爬蟲難以觸及
AI 搜尋優化:讓內容更容易被理解與引用
當基礎做好之後,接下來要思考的是,AI 會不會選擇用你的內容來回答問題,可以從幾個方向加強:
使用結構化資料(Schema)
例如 FAQ Schema、Article Schema,可以幫助系統更快理解內容類型與重點。
更多類型的結構化資料可參考:五分鐘了解結構化資料是什麼,與搜尋引擎進行有效溝通!
提供清楚定義與段落化內容
AI 在生成答案時,很常抓已經整理好的段落,例如:
- 開頭直接給定義(2~3 句講清楚)
- 用 2~3 句講清楚一個概念
- 比較型內容(OOO vs OOO 優缺點比較)
補充數據、研究與具體資訊
帶有數據或案例的內容,比起內容只有概念描述,更有價值。例如:
- 統計資料
- 研究數據
- 實驗結果
- 最新觀察
增加 FAQ 問答內容
因應 Query Fan-Out(查詢擴展)技術,AI 在回答問題時,常會延伸相關提問,因此 FAQ 內容有機會被直接使用,例如:「AI Crawlability 是什麼」就可能延伸到「AI Crawlability 會影響 SEO 嗎」。
而常見問題也有機會出現在 Google 的 People Also Ask 區塊,有利於增加曝光。
AI Crawlability 常見迷思破解
隨著 AI SEO 討論越來越多,市場上也出現不少說法,有些甚至讓人越看越混亂,以下幾個常見迷思,先幫你一次釐清!
內容需要特別切細給 AI 看嗎?
通常不需要。只要內容本身段落清楚、有結構(例如標題、條列、分段),AI 系統就能自動進行 chunking(內容切分)。
舉例來說:一篇文章如果每個段落都有明確主題,例如「優缺點」、「適用族群」、「價格比較」,AI 很容易直接拆成段落來引用。
相反地,如果是一整段沒有分段的長文,AI 在理解上反而會更吃力。
一定要建立 llms.txt 嗎?
目前不是必要條件。
llms.txt 的概念類似 robots.txt,是提供 AI crawler 的額外指引,讓網站可以說明哪些內容可以被使用。不過目前多數 AI crawler,仍然是依照既有的抓取邏輯在運作,並不完全依賴 llms.txt。
而 Google 對這件事的態度相對保守,他們不建議使用,原因在於,AI 的設計本來就是用來理解內容,而不是像傳統爬蟲一樣依賴規則檔案來決定行為。
Google 的立場可參考【Search Central Live Deep Dive】Day1:SEO is Dead?AI 搜尋時代的 SEO 新解讀!|awoo 活動實記的QA問答紀錄。
AI crawler 會取代 Google crawler 嗎?
不會。
目前大多數網站流量,仍然來自 Google 搜尋,Googlebot 依然是最主要的爬蟲來源。AI crawler 的角色比較像補充資料來源,而不是完全取代搜尋引擎。
AI 搜尋會完全取代 SEO 嗎?
不會,但會改變 SEO 的重心。
未來網站優化,會變成同時經營兩件事:
- SEO(搜尋排名與流量)
- AI 搜尋可見度(是否被引用與使用)
AI Crawlability 將成為新一代 SEO 指標
隨著 AI 搜尋的普及,網站可見度的衡量方式也在改變,當使用者詢問「2026 咖啡機推薦」,除了搜尋結果頁,AI 也可能直接給出整理好的答案,這時候,能不能被引用,往往比排名更早影響曝光。
當 AI 搜尋逐漸成為主要資訊入口,AI Crawlability 很可能成為新一代 SEO 的評估基準之一。
想提升 AI 搜尋曝光?從現在開始布局
如果你也在思考:
- 為什麼內容沒有出現在 AI 回答中?
- 哪些頁面有被 AI crawler 抓取?
- 怎麼優化內容,才能提高被引用的機會?
awoo 已協助多個品牌進行 SEO 與 AI 搜尋可見度優化,從網站結構、內容策略到數據分析,找出最適合的成長方式。
如有任何網站優化相關問題與需求、或想瞭解更多 AI SEO/GEO 服務歡迎填寫表單立即諮詢,將有 awoo 專業顧問與您聯繫。
Contact Us
「*」代表必填欄位