

Search Central Live Deep Dive 2025 現地レポート!
awooチームはタイ・バンコクで開催された、Google主催のアジア太平洋地域初となる「Search Central Live Deep Dive」に参加。
3日間にわたる技術カンファレンスには、世界各地の検索エキスパートや開発者が集結し、Google検索の裏側、AIとの融合、コンテンツ戦略、テクニカルSEOなど多岐にわたるテーマが議論されました。
このレポートでは、awooチームが現地で得た知見を日ごとにまとめてご紹介。
Day1の記事では、AI検索時代における新しいSEOの考え方と実践的な戦略をまとめています。
💡 Day1のハイライトを見逃した方はこちら:SEOの時代は終わった?Google公式イベントで語られた、AI検索時代の新たなSEO戦略【Search Central Live Deep Dive Day1 レポート】
Day2のテーマは「テクニカルSEOを深掘り!:インデックスの仕組みを解き明かし、JavaScriptの落とし穴を解消、多言語&コンテンツ最適化の必須テクニック」です。
コンテンツ
Search Central Liveとは?
Search Central Liveは、GoogleのSearch Centralチームが主催する公式イベントで、ウェブサイト運営者、開発者、SEO専門家向けに開催されています。
今回開催された「Search Central Live Deep Dive」は、そのアドバンス版とも言える3日間の集中カンファレンスです。内容もより高度で、検索の根本的な仕組みや最新技術に踏み込んだ議論が展開されました。
このイベントの最大の魅力は、従来の短時間型から、3日間にわたる本格的な学習プログラムへと大きくスケールアップしている点です。以下に、主な注目ポイントをご紹介します。
- Google公式チームとコミュニティの専門家による深掘りセッション
- 実際の成功事例の共有と、技術的なワークショップ
- Search ConsoleやGoogle Trendsといったツールの実践的な活用法解説
- 参加者同士の活発な質疑応答や、国境を越えたネットワーキング
このイベントは、世界のSEO最前線と知見を同期させる、またとない貴重な機会です。私たちがイベントで得た現地の情報とセッションの要点を整理してお届けします。
Day2のサマリ:インデックス重視のSEO戦略とGoogle Trends APIの衝撃
- ランキングよりインデックス!まずはGoogleに登録されることが最重要
- JavaScriptサイトは終わりじゃない。正しいレンダリング処理とリンク設計で道は開ける
- 多言語戦略の肝はhreflangとサイトマップの連携
- 【速報】Google Trends API、ついにベータ版の利用がスタート!
【時系列レポート】Day2全セッションのハイライト
オープニングセッション:ようこそ「インデックス・デー」へ!(10:15)
Day2の冒頭は、Google検索チームによるQ&Aセッションからスタート。短いながらも、テクニカルSEO担当者が日々直面する疑問の核心を突く質問ばかり。理論だけでなく、実践的な技術を学ぶ交流の幕開けです!

Q:Google以外のチャットボットもrobots.txtに従いますか?
A:ケースバイケースです。Googleとしては他社の動きを保証できませんし、robots.txtはあくまで「任意遵守」のプロトコルです。
Q:画像のファイルサイズはクロールバジェットに影響しますか?
A:しません。Googleのクロールバジェットは「ページ単位」で計算され、リソースのサイズには依存しません。ただし、画像や動画が極端に大きいと取得に時間がかかり、ダウンロード完了までクロール全体が遅延、あるいは一時停止する可能性があります。
Q:Googleはクロール効率の観点からレスポンシブデザインのサイトを優遇しますか?
A:特定の技術を優遇したり、特別扱いしたりすることはありません。しかし、アダプティブ配信やダイナミックレンダリングを採用すると、JavaScriptの処理や画像の遅延、再レンダリング負荷が増える傾向があります。
Q:自社サイトのクロールバジェットが有効に使われているか、どう判断すべきですか?
A:Search Consoleの「クロールの統計情報レポート」で2つの指標を確認してください。
- すべての既知のページ
- 「検出 – インデックス未登録」(discovered – not crawled)の項目数
後者の数値が高い場合、サイト内のコンテンツが多すぎてクロールが追いつかない、コンテンツ品質が低く、クロールする価値がないと判断されている、あるいはサーバー/ネットワークエラーがクロールを妨げている可能性があります。
Google検索チームによれば、インデックス化までのプロセスが想像以上に複雑であるとのこと。単にボットがクロールして終わりではなく、次のステップを経ています。
- HTML 解析
- JavaScriptレンダリング
- 重複ページの判定
- メインコンテンツ抽出
- 各種シグナルの取得(Canonical、hreflang、metaタグなど)
- 最終的なインデックス登録とランキング反映
GoogleはHTMLをどう「読む」のか?Webページを分解するプロセス(10:25)
このセッションでは、GooglebotがどのようにWebサイトを理解するのか、その基礎が解説されました。
単にキーワードを詰め込んだり、内部リンクを増やせば終わり、というわけではありません。GoogleはDOM構造の段階から、ページの論理構造を分析しています。
- <head> → titleやmetaなどの情報を取得
- <body> → ナビゲーション(nav)、メインコンテンツ(main content)など各コンテンツ領域を解析
スピーカーが特に強調していたのはメインコンテンツの重要性です。
Googleはページの“主役”となるコンテンツを特定しようとします。正しくマークアップされていなかったり、内容が薄かったり、ナビゲーションやサイドバーの情報と混在していたりすると、Googleの判断を誤らせる可能性があります。
この段階でGooglebotが解析する主な情報は以下の通りです。
- canonicalタグ
- hreflang(言語対応)
- robotsタグ
- 各種リンクやJavaScriptリソースの可視性
また、GooglebotはURL構造やJavaScriptの実行権限をもとに、どのページをクロールできるか、どれを除外するかも判断します。
公式参考資料:Google のリンクに関するベスト プラクティス

インデックスをコントロールする方法(10:30)
続くセッションは、より技術的な内容に。Googleに対して「これはクロール不要」「これはインデックスしないでほしい」と伝える具体的な方法が解説されました。Googleは検索プロセスを2つの段階に分けており、それぞれで制御方法が異なります。
1️⃣ Crawling(クロール可否の制御)
robots.txt を使用。特定のフォルダやリソース(JavaScript、CSS、画像など)へのGooglebotアクセスをブロックすることができます。
2️⃣ Indexing(インデックス可否の制御)
<meta name=”robots”> タグを使用。より詳細なルールを指定できます。
| 指令名称(directive) | 機能説明 |
| noindex | ページを検索エンジンのインデックスに登録させない |
| nofollow | このページのリンク評価を渡さない |
| nosnippet | 検索結果にテキストスニペット(説明文)を表示しない |
| data-nosnippet | 指定範囲のテキストをスニペットから除外 |
| max-snippet | スニペットの最大文字数を指定(-1: 無制限, 0: 非表示) |
| max-image-preview | 画像プレビューの最大サイズを指定(none / standard / large) |
| max-video-preview | 動画プレビューの最大秒数を指定 |
| noimageindex | 画像をインデックスさせない |
| no-translate | ページの翻訳バージョンを提供しない(翻訳誤り回避など) |
| unavailable_after | 指定日時以降、このページを検索結果から削除 |
会場からの質問
Q:JavaScriptでmeta robotsタグを追加できますか?
A:可能です。ただし、JavaScriptのレンダリングが完了してからでないと解析されないため、反映まで時間がかかります。
公式参考資料:Google がサポートしている meta タグと属性
Googleの説明によると、nofollowは「to prevent passing on ranking credit(ランキング評価を渡さないため)」のための指令です。
つまり、SEO業界で長年語られてきた「リンクジュース(link juice)」の存在をGoogleが公式に認めた、と解釈できる非常に興味深い一言でした。
⚡ライトニングトーク:JavaScriptレンダリングとの向き合い方
冒頭で登壇者は「GaryのサイトでさえJavaScriptを多用している」と紹介。
つまり、このセッションの核心は「JavaScriptで生成されたコンテンツを、いかにクローラーに認識させるか」という点です。3つの実例を通じて、JavaScriptとSEOの複雑な関係を解き明かします。
1️⃣ 事例①:コンテンツSEOとテクニカルSEOは協力すべき
「テクニカルSEO vs コンテンツ」という長年の論争。登壇者の見解は明快で、「両者は切り離せない、相互補完すべきもの」と主張します。
例えば、ECサイトが長文のブログ記事ばかりを追加していると、Googleがそのサイトを「取引志向ではない」と判断し、自然検索トラフィックが逆に落ちる可能性があります。
成功するSEO戦略は、サイトの現状分析から始め、On-page SEO(タイトル/ディスクリプション最適化など)、コンテンツ配置、サイトのカテゴリ設計を統合的に計画する必要があります。
📌 登壇者の一言:「「コンテンツは主役、技術はそれを支える体幹である。」

登壇者:https://www.linkedin.com/in/yisan-lee-4bb69b160/
2️⃣ 事例②:JavaScriptレンダリング依存サイトのSEO復活法
登壇者によれば、実に98.9%のサイトが何らかの形でJavaScriptを利用しており、そのタイプは大きく2つに分かれます。
- 装飾目的(例:WordPress, Shopify)
- コンテンツ生成の核として使用(例:React, Vue.js)
彼が紹介したのは、悲惨な事例でした。
もともと静的HTMLだったサイトを全面的にJavaScriptレンダリングへ移行した結果、SEOパフォーマンスが急落。原因は明白で、クローラーがメインコンテンツを全く認識できなかったのです。
もし高品質なページがインデックスされない場合、JavaScriptレンダリングの問題を疑うべきと警告しました。
自己診断の3ステップ
- 01. ブラウザの「ページのソースを表示」で、メインコンテンツのテキストが表示されるか確認する
- 02. Google Search ConsoleのURL検査ツールとインデックスレポートで状態をチェック
- 03. 「クロール済み – インデックス未登録」や「ソフト 404」が多い場合は要注意
よくあるJavaScriptの問題点
- JSで動的にmetaタグを生成している
- robots.txtでCSS/JSファイルをブロックしている
- 内部リンク構造をJSで動的生成している
- サイトマップが長期間更新されていない
- HTML形式のcanonicalタグが存在しない
📌 重要なポイント:JavaScript自体が悪ではない。問題はその使い方にある。

登壇者:https://www.linkedin.com/in/wasin-mekkit?fromQR=1
3️⃣ 事例③:JavaScript SEOの惨事からの大逆転劇
登壇者のLoki Yan氏が紹介したのは、Angularベースで構築されたサイトのケース。
レンダリング後のコンテンツをGooglebotが正常に取得できず、サイトの検索流入はほぼゼロという深刻な状態に陥っていました。
復活までの改善プロセス:
開発者ツール、Google Search Console、Screaming Frogなどを駆使して問題点を特定し、以下の一連の最適化を段階的に実施しました。
- JavaScript構造の簡素化
- 不要なAPIコールの削除
- 重要でないJSの遅延読み込み
- ファイルの分割・再パッケージ化による読み込み効率改善
成果:クリック数がほぼゼロの状態から、1年後には80万、2年後には2400万クリックを達成。
📌 印象的な一言:「JavaScriptを理解すれば、エンジニアに正しい“挑戦”ができる(=技術を知っているからこそ、適切な質問と改善要望が出せる)」

登壇者: Xinyuan (Loki) Yan
Googleに優しいJavaScriptとは?(11:10)
Googlebotは、JavaScriptで生成されたコンテンツを理解できるものの、それには条件があります。
登壇者は、Googlebotがコンテンツを認識できなくなる典型的な要因を具体的に解説しました。
🚫 JavaScript SEOでのよくある落とし穴リスト
- レンダリング後のHTMLにコンテンツがない: GooglebotはJSをレンダリングしますが、その結果DOMにコンテンツが表示されなければ、当然データも取得できません。
- GooglebotがJSを呼び出せない:APIにログインや権限設定が必要な場合、Googlebotはアクセスできずコンテンツを取得できません。
- JSの実行条件が複雑すぎる: コンテンツを表示するトリガーが深すぎたり、実行順序が不安定だったりすると、クロールに失敗します。
- ユーザー操作(クリックなど)で初めて表示されるコンテンツ: 「もっと見る」をクリックしないと出ない内容などは、Googlebotは操作しないため読まれません。また、Googlebotはページ先頭から約10,000pxまでしか読み取らないため、それ以降にある情報はほぼ認識されません。
- URLに#(ハッシュ)を使っている: /#productsのようなハッシュ付きURLはサーバーに新しいリクエストを送らないため、クローラーは別ページとして認識しません。
- SPA(シングルページアプリケーション)のソフト404問題: 単一ページアプリでコンテンツに問題があっても、HTTPステータスコードが正しく返らない場合、Googlebotはソフト404と誤認します。

Googleが見る「ページ内容」の理解プロセス(11:30)
このセッションは基本に立ち返り、Googleがページ内容をどう解釈しているのかを解説しました。
登壇者は「Googleはページ全体を一律に評価するわけではない」と強調。ページ内の各領域ごとに重要度を付けて評価します。
- Header(ヘッダー) 👉 重要度:低
- Nav(ナビゲーション) 👉 重要度:低
- Main Content(メインコンテンツ) 👉 最重要!
つまり、本来フッターにあるべきカテゴリリンクや、CVRの低いタグページを無理やりメインコンテンツ領域に置くと、Googleがそれを「最重要情報」と誤認し、結果的にサイト全体のコンテンツ評価を損なう可能性があります。
参考資料:General Guidelines
ソフト 404 とは?どんな時に判定される?
多くの人が混乱しがちな「ソフト404」についても解説がありました。「ソフト404」は実際の404エラーではなく、「ページは存在する(ステータスコードは200 OK)が、中身がエラーページのように見える」状態を指します。判定される主な原因は以下の通りです。
- コンテンツが極端に少ない(数行のテキストのみ、など)
- CMSやサーバーのエラーでデータが読み込めていない
- JavaScript主体のサイトでレンダリングに失敗
- Google側の判定ミス(バグの可能性もあり)
📌 ポイント:問題ないはずのページがソフト404と判定されたら、Google Search Consoleのインデックスレポートで、コンテンツ品質/技術的エラー/レンダリング不具合のどれが原因かを必ず確認すべきです。
このセッションをもって午前の部は終了。
ランチ休憩の後は、SEOにおける長年のテーマ「重複コンテンツ」と「国際化対応」を徹底的に掘り下げます。
重複コンテンツの正しい対処法(12:45)
まず押さえておきたいのは、重複コンテンツ ≠ コピーコンテンツという点です。
ここでいう重複とは、Googleが「どのページをインデックス・ランキング対象にすべきか判断できない状態」を指します。
重複コンテンツの判定プロセス:
- 実質的に内容が重複しているか(同じトピック、段落、構成など)を判断
- どのページが「正」であるかを示すcanonical URL(正規URL)を選定
多言語サイトも注意が必要です。言語は違えどコンテンツの構成が似ている場合、hreflangタグで言語・地域を明示しないと、重複コンテンツと見なされ、Googleがランダムに1つのバージョンしかインデックスしないことがあります。
Googleが正規ページを判断する際に頼りにする「シグナル」は以下の通りです。
- ユーザー体験のシグナル: ユーザーは本当に、これらの類似コンテンツを両方必要としているか?
- 技術的なシグナル: 301リダイレクト、canonicalタグ、サイトマップが正しく設定されているか?
- 言語と地域のシグナル: hreflangタグで言語・地域が明確に区別されているか?
📌 推奨される対処法:
- 301リダイレクトで正規ページに統合する
- HTTPSのステータスコードを正しく返す
- <link rel=”canonical”> を正しく設定する
- 多言語ページにはhreflangで地域・言語を明示
- Googleを迷わせないよう、一貫性のある明確なシグナルを送信する
⚡ライトニングトーク:サイト移転はただの引越しじゃない!やり方を間違えればSEOは崩壊(12:57)
このセッションでは、楽天のテクニカルSEO責任者が、サイト移転・統合プロジェクトで直面したリアルな課題を共有しました。
直面した主な課題
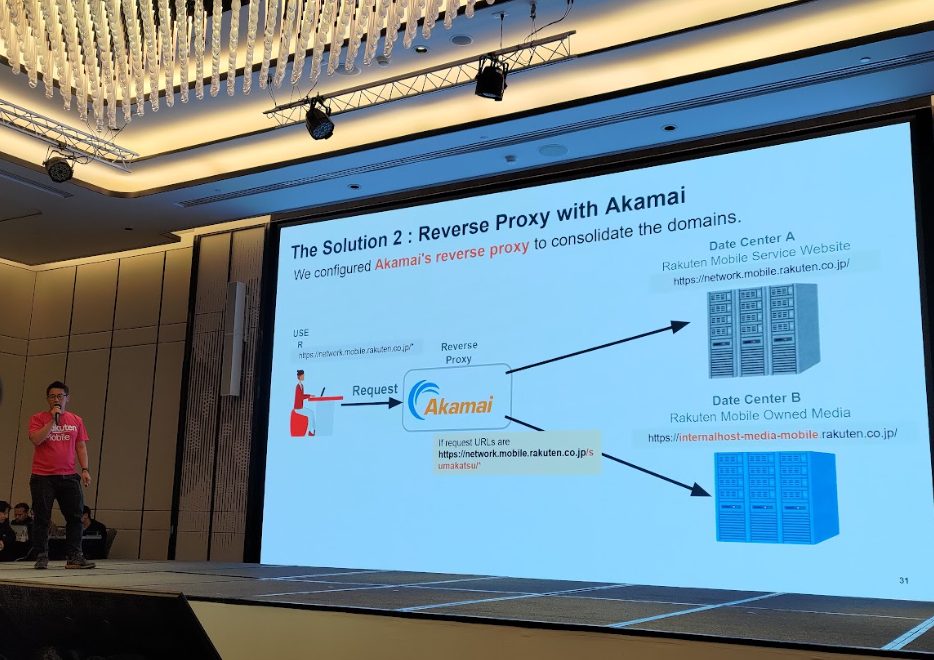
- 301リダイレクトリストの不備:初期対応が不十分だったため、大量のページリンクが無効化され、トラフィックが急減。
- Akamaiのリバースプロキシによるトラフィック制御:移転作業中もユーザー体験を途切れさせないよう、Akamaiのリバースプロキシを活用してトラフィックを最適に制御。
Akamaiのリバースプロキシ技術を使い、2つの異なるソースから来るサイトデータを統合。結果、トラフィックが9倍に成長するという驚異的な成果を達成したとのことです。
登壇者からの重要アドバイス: コンテンツは可能な限りメインドメイン配下に置くこと。独立したサブドメインに置くよりも、メインドメイン直下にある方がパフォーマンスは向上する傾向がある。
登壇者:https://www.linkedin.com/in/akihiro-miyata-36158791/
構造化データはなぜ検索の「ゴールドラッシュ」なのか?(13:05)
GoogleのGary Illyes氏はこのセッションの冒頭でこう強調しました。
「構造化データとは、私たちがページ内の“金塊”をより早く見つけるための仕組みだ。」
商品、記事、動画、画像など、どんなコンテンツであれ、Googleがサポートする構造化データでマークアップすることで、検索エンジンはそのページの要点をスピーディかつ正確に理解できます。特にAI検索やマルチメディアの重要性が増す今、これらのマークアップはコンテンツが検索に取り込まれるための“前提条件”になりつつあります。
また、メディアコンテンツ(画像・動画)のインデックス処理は、HTMLのインデックス処理とは別で行われ、その橋渡し役となるのが構造化データです。これにより、Googleは「これは何か」「どう表示すべきか」「ユーザーに見せる価値はあるか」を理解しやすくなります。構造化データは、いわば「この記事には動画が含まれる」「この画像は商品のメインビジュアルである」「このテキストはレビューの要約である」とGoogleに教えるためのラベル。明確で正確であるほど、より魅力的な形で検索結果に表示されるチャンスが高まります。
公式参考資料:構造化データに関する一般的なガイドライン

画像と動画のSEO。メディアコンテンツでユーザーを惹きつける方法(13:17~13:27)
しばしば「装飾」と見なされがちな画像と動画ですが、現在では検索結果における重要なコンテンツとなっており、クロールされるかどうか・どう表示されるかがSEOパフォーマンスに直結します。
画像をインデックスさせるには?
Googleは<img>タグのsrc, alt, title属性や<picture>タグから画像の内容を理解します。
- ・alt属性が最も重要。 内容を的確に説明するテキストを必ず記述してください。
- ・title属性は弱いシグナルですが、補足情報として役立ちます。
注意:CSSで指定する背景画像(background-image)は検索エンジンにインデックスされません。
また、記事のメイン画像や商品画像などを構造化データに含めることも有効ですが、対象はページ内容と強く関連するメイン画像に限定してください。無関係な背景画像が多い場合は、クロールをブロックしてクロールバジェットを節約することも検討しましょう。
Q. AI生成画像をブロックすべきですか?
A. 「任意です。」とGoogleの回答は現実的。ユーザーが検索するような価値あるコンテンツであれば表示される可能性はありますが、ハルシネーション(AIによる誤情報)のリスクには注意が必要です。
Q. 動画の検索露出を高めるには?
A. 動画が表示されるのはYouTubeだけではありません。通常の検索結果、動画検索、Google Discoverなど、露出機会は拡大しています。Googleはキーモーメント(動画内の主要な場面)やプレビューといったリッチな機能も強化しています。
動画の検索露出を高めるための5つのアクション
- ページ自体のコンテンツを充実させる(動画だけで本文なしはNG)
- 動画をメインコンテンツエリアの見やすい位置に埋め込む
- 動画の構造化データを追加する(JSON-LD形式を推奨)
- 動画サイトマップを用意し、検索エンジンに内容を明示
- PC・モバイル両方で再生可能か確認し、埋め込みエラーを防止
Q. AI生成の動画はdisallowすべき?
A. Googleの回答は画像と同じく「任意」とのこと。ただし、コンテンツの品質と正確性、特にAIハルシネーションには細心の注意を払うよう、再度注意喚起がありました。

多言語サイトの最適化。国際SEOとローカライゼーション戦略の要点(13:45)
国際SEOで欠かせないキーワードは 「hreflang + ローカルシグナル」。
異なる言語バージョンや複数の国・地域を対象とするサイト運営では、この設定を怠ると検索結果が正しく表示されません。
hreflangの正しい設定方法
hreflangは、Googleに対して「このページには、これらの言語・地域に対応する別バージョンがあります」と伝えるためのタグです。HTMLの<head>内に<link rel=”alternate” hreflang=”xx-YY”>を追加するか、サイトマップで対応関係を記述するのが一般的です。
📌 よくある間違い:
- ・AページからBページへのhreflangは設定されているが、BからAへの設定がない(相互参照になっていない)
- ・言語コードが間違っている(❌ jp, UK ➜ ✅ ja, GB)
- ・地域だけ指定して言語を指定していない(❌ hreflang=”sg” ➜ ✅ hreflang=”en-sg”)
正しいhreflangは「双方向」かつ「言語+地域」を正確に記述する必要があります。
Googleはどの地域のユーザーにどのページを見せるか?
hreflangに加え、Googleは以下のシグナルを総合的に判断します。
- ccTLD(国別コードトップレベルドメイン。例:.jp, .co.uk)
- サーバーの地理的な位置
- その他のローカライゼーション情報(使用言語、通貨、地域限定リンク、ビジネスプロフィールなど)
Q. 機械翻訳で多言語ページを生成しても良い?
A. Googleの答えはシンプル。「翻訳の品質次第」。現地の言葉遣いや文化に合わない不自然なコンテンツは、良いユーザー体験を提供できず、SEO効果も期待できません。
国際SEOは単なる翻訳ではなく、「ローカライズ=現地ユーザーにとって自然かつ有用な体験」がカギとなります。

⚡ライトニングトーク:GSCとTrends活用術!国際SEOの実践(14:00)
このセッションでは、Google Search Console(GSC)とGoogle Trendsという2つのツールを活用した国際SEOのテクニックが紹介されました。
1️⃣ Google Search Consoleによる多言語サイト管理術
登壇者は「多言語・多地域サイトを運営しているなら、GSCに追加する際はドメイン単位ではなくURL単位(プロパティ)で管理すべき」と強調。これにより、言語ごと(例:/ja/, /en/)にデータを分離して追跡でき、より詳細な分析と最適化が可能になります。APIやScreaming Frogのようなクローラーツールと組み合わせることで、さらに高度な分析が実現します。
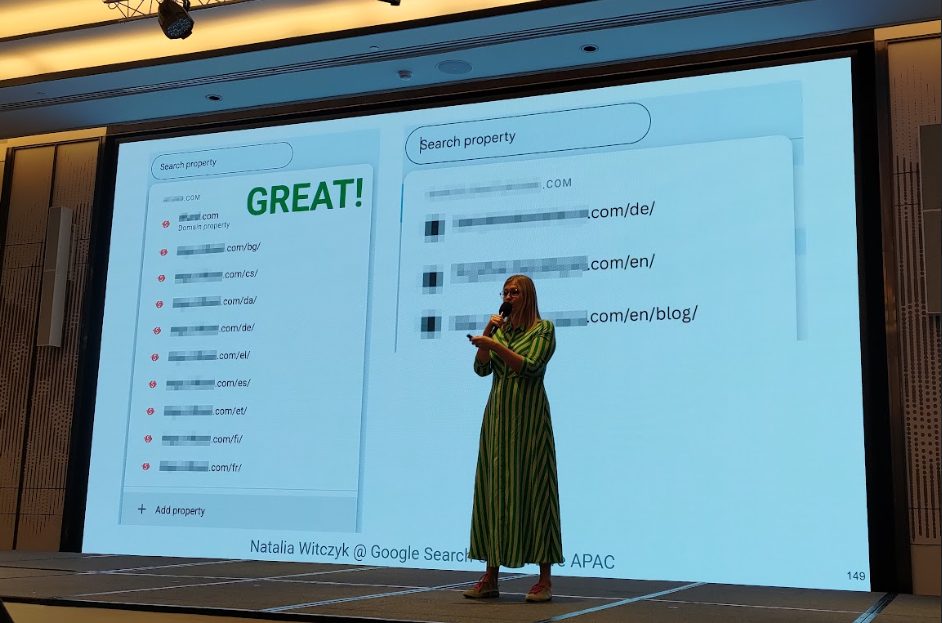
登壇者:https://es.linkedin.com/in/nataliawitczyk
2️⃣ Google Trendsを使った多言語キーワード調査
二人目の登壇者は、Google Trendsを用いて多言語のキーワードからトレンドを観察していた取り組みを共有しました。
さらにGoogleへの“改善要望リスト”として以下を挙げました。
- Google TrendsにGoogle Discoverのデータを追加してほしい
- X (旧Twitter) のように、国を横断したグローバルなトレンドを見られるようにしてほしい
- 国だけでなく「言語」でフィルタリングできるようにしてほしい
- より具体的な検索ボリュームデータと、APIの機能拡充を!
これは多くのSEO専門家の心の声を代弁する、熱意のこもったウィッシュリストでした。

ポスターセッション:インデックスと多言語対応の実践例(14:18)
休憩前には、GoogleがSearch Central Liveで初めて試みる「ポスターセッション」が開催されました。参加者は会場を自由に歩き回り、各テーマの専門家と直接質問や意見交換ができます。特にインデックスや多言語最適化のようにケースバイケースで答えが変わるテーマに適した形式でした。
共有されたテーマの例
- 5分でできるサイトヘルスチェック
- 多言語SEOの実践報告(日本、韓国、ポーランドの事例)
例えば、ポーランドの金融プラットフォームLOANDOのチームは、自社サービスをルーマニア、ウクライナ、チェコなどの新市場に展開した事例を紹介。当初はトラフィック低下に苦しんだものの、ローカライズされたコンテンツ戦略や広報活動、現地の法規制遵守といった多角的なアプローチでSEOを強化し、最終的にトラフィックと収益の成長を達成したプロセスを解説しました。

一方、越境ECをテーマにした登壇者は、言語の観点から非常に興味深い知見を共有しました。
アメリカの製品を日本市場で販売する際、「Tシャツ」という一つの商品をどう翻訳するかが大きな課題だったと言います。日本では「丸首Tシャツ」「半袖Tシャツ」「コットンTシャツ」など、ユーザーの検索クエリは非常に多様です。
そこで彼らは、市場調査や年代別の言葉遣いの分析に加え、入力時のキーボード操作までシミュレーションしたといいます。最終的に、機械学習ベースの「商品名翻訳モデル」を構築し、日本市場に商品を大量投入する際に、現地のユーザーが使う検索ワードに最適化された商品名を自動生成できるようにしたそうです。

このインタラクティブなセッションは、イベントに「国際SEOの情報交換会」のような活気をもたらしていました。
何が本当の「インデックスシグナル」なのか?Googleが公式回答!(15:05)
「Google はどんなシグナルをもとにインデックスするのか?」
Gary Illyes 氏が会場でクイズ形式のセッションを実施。驚くべきことに、「ドメインエイジ」「XMLサイトマップ」「E-E-A-T」といった、多くの人が重要だと信じていた項目は、実はインデックスの直接的なシグナルではないことが明かされました。
✅ インデックスシグナル(影響する要素)
- 国 (Country)
- 言語(Language)
- HTTPS / サイトの安全性
- コアウェブバイタル (Core Web Vitals)
- Dofollowリンク
- コンテンツの鮮度 (Recency)
- スパムポリシー違反
❌ インデックスシグナルではないもの
- ドメインの年齢や履歴
- 構造化データ
- XMLサイトマップ
- クロールのしやすさ (Crawlability)
- コンテンツの深さや網羅性
- 内部リンク構造の妥当性
- コンテンツの可読性
- トピックの権威性 (Topical Authority)
- 検索意図との整合性
- HTML内のキーワード
- E-E-A-T (経験、専門性、権威性、信頼性)
- hreflangタグ
- リンクの増加速度 (Link Velocity)

このリストは、Googleがその場で公開したものです。あなたの常識は覆されたでしょうか?
ここで改めて強調されたのは、私たちが知る多くのSEOテクニックは、必ずしも「インデックスされるかどうか」に直結するわけではない、ということです。特にhreflangやE-E-A-T、構造化データは、Googleのコンテンツ理解やランキング向上には重要ですが、「インデックスされるかどうかには影響しないことがわかりました。
どのようなコンテンツが Google にインデックスされるのか(15:25~15:45)
セッションは、インデックスの「ブラックボックス」の核心へ。Gary Illyes氏は「クロールされた全てのページがインデックスされるわけではない。Googleは選別している」と断言。インデックスされるには、「実用性・信頼性」を備えた高品質コンテンツであることが必須です。
🚫 インデックスされない主な原因
- ページにnoindexが設定されている
- サイト側で「期限切れ(expired)」としてマークされている
- ソフト404 エラー
- 重複コンテンツ
- スパムまたはポリシー違反(違反詳細は非公開。「それは秘密😏」とGary氏)
📌 GSCのこの2つのステータスは、慌てて修正不要!
- 検出 – インデックス未登録 (Discovered – currently not indexed):
ページは発見済みだが、クロールは保留中。これは、サイトに過負荷をかけないための配慮であり、後で再試行されます。 - クロール済み – インデックス未登録 (Crawled – currently not indexed):
クロールはしたが、データベースに登録する価値はないと判断された状態。無理に修正せず、まずは様子見でOK。
Gary氏のアドバイスは明確です。「GSCのレポートに表示される未登録やエラーが、必ずしも“修正すべき問題”とは限らない。単なる一時的な状態であることも多い」。インデックスのロジックをより深く理解したいなら、以下の公式参考資料に立ち返ることを推奨していました。
公式参考資料:Google の検索エンジンの仕組み、検索結果と掲載順位について、クロールとインデックス登録に関するトピックの概要
Google Trends API登場!データで検索トレンドを掴む(15:50)
Day2の最後は、Google Trendsを使った参加型のミニゲームで締めくくられました。「過去5年間、YouTubeで『パッタイ(タイ風焼きそば)』と一緒に検索された関連トピック第2位は?」といったクイズに挑戦。笑いと驚きに包まれながら、Trends の使い方を実体験できるひと幕となりました。
Google Trendsは、キーワード比較、ユーザーの検索意図の把握、地域や期間でのトレンド分析など、Web検索から画像、ニュース、ショッピング、YouTubeまで幅広く対応しています。
- リアルタイムでの変化を可視化(過去4/24/48時間、7日間)
- 検索ボリューム・発生日時・分類データを提供
- ニュースリンクや 検索エンジン結果ページ(SERP)と連携し、流入方向を即座に把握
季節イベントやセール流入を狙うなら、1〜2か月前の準備が必須。
【超重要】Google Trends API、ついにベータ版の利用申請がスタート!
そして最後に待望のニュースが!
Google Trends API がついに試用申請可能に。会場からは歓声が上がりました。Google Trends
Google Trends APIで可能になること
- スケーリングされたデータの取得(0〜100の相対値ではなく、絶対的な比率を保ったままデータを取得可能に。)
- 時間範囲は 直近48時間〜過去5年
- 表示は 日/週/月/年 の自由選択
- 国・カテゴリ別のフィルタリングに対応
- 「バナナ vs リンゴ」のように、比較対象を変えても基準がリセットされない、一貫したデータ分析が可能に。
トレンドを定常的に追跡する必要があるチームにとって、これはコンテンツ戦略とSEO施策を飛躍させる強力な武器となります。

❓Q&Aセッション:現場の疑問にGoogle担当者が回答!
イベントの締めくくりは恒例のQ&Aタイム。GeminiからTrends API、インデックスのロジックまで、核心に迫る質問が飛び交いました。
Q1. Geminiでの検索はGoogle Trendsのデータに含まれますか?
A1. いいえ、まだ含まれていません。
Q2. Google Trends APIに「急上昇中」機能はありますか?
A2. いいえ、現時点ではサポートされていません。
Q3. ChatGPTがGoogleのインデックスデータを使っているという噂は本当ですか?
A3.(登壇者は)知らないし、気にしていないし、噂にはコメントしない、とのことでした(笑)。
Q4. SSR(サーバーサイドレンダリング)はCSR(クライアントサイドレンダリング)よりSEOで有利ですか?
A4. 直接的な優位性はありません。しかし、CSRはインデックス周りで問題が発生しやすい傾向があります。
Q5. Googleはソフト404をどう処理しますか?過去にクロールしたコンテンツを使いますか?
A5. 使いません。ソフト404と判定されたページはインデックスから削除される可能性があり、過去のデータで代替されることはありません。
Q6. Google Trendsの「検索キーワード」と「トピック」の違いは?
A6. 「キーワード」は入力された具体的な語句そのもの。「トピック」は概念であり、スペルミスや関連語句を自動で含みますが、個別の語句は特定できません。
Q7. 構造化データがSEOに役立つというのは、リッチリザルトが表示されるものだけですか?
A7. 構造化データはランキングに直接影響しません。役には立ちますが、その効果を具体的に数値化するのは困難です。
Q8. 「クロール済み – インデックス未登録」のページはどうすればいいですか?
A8. 一般的に、コンテンツの質が低いか、技術的な問題があることを意味します。「このコンテンツはインデックスする価値がある」とGooglebotに証明する必要があります。サイトマップはページの発見には役立ちますが、インデックス登録自体への貢献は限定的です。
Q9. Googleウェブキャッシュ機能が廃止されたのはなぜですか?代替ツールは出ますか?
A9. 公式な理由は明かされていませんが、「利用率の低さ」と「運用コストの高さ」が推測されます。現時点で代替ツールをリリースする計画はありません。
Q10. フィリピンのように複数の公用語がある国では、どう言語の最適化をすればよいですか?
A10. フィリピンやインドのように、多言語話者の比率が拮抗している国に対する完璧な解決策は、今のところありません。「統一言語ができるのを待つしかないね!」とGoogleは冗談めかして答えていました。
awooの考察
Day2のセッションを通じて、「SEOの技術的な基盤への投資は、今なお価値が高い」ということを再認識しました。
JavaScriptサイトのレンダリング、多言語サイトでのhreflangの正しい設定、インデックス判定のロジックなど、一つひとつは細かな技術要素に見えるかもしれません。しかし、そのどれもが、サイトのインデックスと検索順位に大きな影響を与えうるのです。
Gary Illyes氏が述べた「AIのためにSEOという名前を変える必要はない」という言葉は、非常に的を射ています。だからこそ、私たちはSEOの原点である技術に立ち返り、自社のコンテンツが検索エンジンに正しく「見つけられ」、正しく「理解され」、そして検索結果に「適切に配置される」ための土台を固め続ける必要があります。
これこそが、私たちawooチームがこのイベントに参加し、最前線の技術トレンドと思考法を吸収し続ける理由です。得られた知見を、お客様のビジネス成長に繋がる戦略へと転換していきます。
🔗 他の日のレポートもチェック
◀️ SEOの時代は終わった?Google公式イベントで語られた、AI検索時代の新たなSEO戦略【Search Central Live Deep Dive Day1 レポート】
まとめ
3日間にわたるSearch Central Live Deep Diveは、情報がぎっしり詰まったカンファレンスであるだけでなく、世界中の検索エキスパートと交流できる貴重な場でもありました。awooは引き続き最新トレンドを追いかけ、実践的なノウハウを皆様に共有してまいります。
次回の記事では Day3 の内容をお届けします。テーマは 「検索結果の表示ロジック× Search Console の課題診断 × トレンドインサイト実践」。ぜひご期待ください!
▎関連記事:專業 SEO 公司如何挑選?4大挑選原則讓你一次搞懂(台湾ブログ)
▎関連記事:【2025最新版】SEO是什麼? SEO怎麼做? SEO搜尋引擎排名優化一次搞懂(台湾ブログ)


