

Search Central Live Deep Dive 2025 現地レポート!
awooチームはタイ・バンコクで開催された、Google主催のアジア太平洋地域初となる「Search Central Live Deep Dive」に参加。
3日間にわたる技術カンファレンスには、世界各地の検索エキスパートや開発者が集結し、Google検索の裏側、AIとの融合、コンテンツ戦略、テクニカルSEOなど多岐にわたるテーマが議論されました。
Day1ではAI時代のマクロな戦略が、Day2ではインデックスと技術的な詳細を徹底的に解剖。そして迎えた、最も重要な最終日。これまでの全ての伏線が回収され、SEOの究極の問いに直結するテーマです。
- Googleはコンテンツの「品質」をどう判断しているのか?
- 検索結果ページ(SERP)はどのように生成されるのか?
- そして、流入トラフィックの変動に直面したとき、我々はどうデータを駆使して分析し、最適化すべきなのか?
まさにSEO担当者にとって「本丸」といえる議題が集約された一日でした。
💡 Day1のハイライトはこちら:SEOの時代は終わった?Google公式イベントで語られた、AI検索時代の新たなSEO戦略【Search Central Live Deep Dive Day1 レポート】
💡Day2のハイライトはこちら:インデックスが勝敗を分ける! テクニカルSEO×JavaScript×多言語サイト戦略 完全ガイド【Search Central Live Deep Dive Day2 レポート】
まずはぜひDay1の記事をご覧ください。そこでは、AI検索時代における新しいSEOの考え方と実践的な戦略を整理しています。
本シリーズでは、各日ごとのテーマに沿って、awooチームが現地で得た一次的な観察と重要ポイントをまとめています。
本記事では3日目の「品質とランキングの真実 。 ユーザー意図から紐解くAI時代の新SEO戦略」をテーマにお届けします。
コンテンツ
Search Central Liveとは?
Search Central Liveは、GoogleのSearch Centralチームが主催する公式イベントで、ウェブサイト運営者、開発者、SEO専門家向けに開催されています。
今回開催された「Search Central Live Deep Dive」は、そのアドバンス版とも言える3日間の集中カンファレンスです。内容もより高度で、検索の根本的な仕組みや最新技術に踏み込んだ議論が展開されました。
このイベントの最大の魅力は、従来の短時間型から、3日間にわたる本格的な学習プログラムへと大きくスケールアップしている点です。以下に、主な注目ポイントをご紹介します。
- Google公式チームとコミュニティの専門家による深掘りセッション
- 実際の成功事例の共有と、技術的なワークショップ
- Search ConsoleやGoogle Trendsといったツールの実践的な活用法解説
- 参加者同士の活発な質疑応答や、国境を越えたネットワーキング
このイベントは、世界のSEO最前線と知見を同期させる、またとない貴重な機会です。私たちがイベントで得た現地の情報とセッションの要点を整理してお届けします。
Day3のサマリ:品質とユーザー体験が決める、AI時代のSEO新戦略
- 品質はSEOの核心。ただしE-E-A-Tは直接的なランキング要因ではない:Googleチームはコンテンツ品質の重要性を強調し、「労力(Effort)」「独自性(Originality)」「才能(Talent)」「正確性(Accuracy)」という4つの評価指標を提示。一方で、E-E-A-Tはあくまで評価者向けのガイドラインであり、アルゴリズムの直接的なシグナルではないと改めて明言。
- ユーザー意図と「混沌のジャーニー」の再定義:SEOはキーワード最適化を超えて、ユーザー体験を予測(Experience Forecasting)し、複数チャネルにまたがる複雑な購買行動の中でブランドロイヤルティを築く戦略へと進化。
- 新たな脅威、サイト内検索スパム(Site Search Spam):「検索留痕」とも呼ばれる新手の攻撃手法が紹介され、検出・防御の具体策も議論に。サイトセキュリティにおけるテクニカルSEOの重要性が浮き彫りに。
- データ駆動のトラブルシューティングと最適化:GSC(Search Console)、GA4、Google Trends を組み合わせたトラフィック減少の原因究明とキーワード調査や改善施策へつなげる実践ノウハウを紹介。さらに、GSCの大量データエクスポート機能の高度な活用法も注目を集めました。
【時系列レポート】Day3全セッションのハイライト
オープニングセッション:検索表示とランキングの世界へようこそ!(10:15)
3日目のオープニングは、会場全体に期待感が満ちあふれていました。雰囲気は前日までとはまるで別物。もし前の2日間が「基礎工事と骨組み作り」だったとすれば、この日はまさに建物の外観と内装を決める仕上げの段階です。司会者は軽快な口調で「検索結果とランキング徹底解剖の日へようこそ!」と参加者を迎え、この日のセッションが検索結果ページ(SERP)の背後にある謎に迫る核心的な内容であることを予告しました。

ユーザーのクエリを理解する(10:25)
このセッションは検索エンジンの出発点ともいえる「ユーザーのクエリ理解」から始まりました。Googleが、雑然とした文字列をどのように解釈し、精緻な「意図」に変換しているのか、そのプロセスが詳細に解説されました。
Googleはキーワードをどう理解し、処理しているのか
あなたが検索ボックスに「バンコク フライドチキン おすすめ」と入力した瞬間、Googleの内部では、その検索意図をシステムが理解できる命令に変換するための、複雑な「翻訳」作業が行われています。
- トークン分割(Segmentation):クエリを意味の最小単位に分解。
- 不要語の除去(Cleaning up):本質に影響しない不要な単語を削除。
- エンティティ認識(Recognize the Entity):クエリに含まれる重要な要素(ブランド、地名、人名など)を特定。「バンコク」は地名、「フライドチキン」は食べ物のカテゴリ、といった具合に識別されます。
- クエリ拡張(Expansion):文脈に基づき、より多くの関連結果をカバーできるようクエリを拡張します。
- 同義語システム(Synonyms System):もっとも重要なステップ文脈に応じてトークンを対応する同義語にマッチさせます。例えば、「fried chicken place in bangkok」というクエリでは、「place」は「location」や「restaurant」と理解され、「bangkok」は「bkk」に対応付けられます。さらに、「同階層の単語(siblings)」も見つけ出します。ユーザーが「Canon vs Nikon」と検索すれば、システムはこれが2つのカメラブランドの比較であると理解します。

つまりGoogleは単なる文字列一致を超え、概念やエンティティの関係性まで理解しています。たとえば「おすすめの一眼レフ」とだけ検索しても、裏側ではCanonとNikonといった競合ブランドが“暗黙の候補”として浮かび上がるのです。
したがって、SEOに求められるのは「概念レベルの競合意識」。ユーザーの“比較したい心理”を前提に、コンテンツを設計する必要があります。
会場ではこの点について質疑応答が行われました。
Q: 英語で、英語以外の単語を検索した場合、Googleは認識できますか?
A: ケースバイケースです。「pad thai」のような世界的に有名な言葉なら、多少スペルを間違えても見つかります。しかし、よりマイナーな「kao pad rod fai(タイの鉄道チャーハン)」のような言葉は、スペルミスがあると推測して修正候補を提示することになるでしょう。同様に、システムは時として「湯包(タンパオ)」と「小籠包(ショウロンポウ)」のような、地域に根差した言葉の違いを区別できないこともあります。
キーワードマッチから多因子ランキングへ
登壇者は次に、2000年代の検索理論を振り返りました。当時のSEOは単純で、キーワードをトークン化し、ウェブページ内での出現頻度を計算するだけのものでした。
技術的な視点で見ると、基本的な処理フローは以下の通りです。
- トークン化(Tokenization):まず、ユーザーのクエリをトークンに分割します。これが検索意図を理解する第一歩です。
- ポスティングリスト生成(Posting List):各トークンに対応する「含まれるURLリスト」を作成。
- カウントと初期マッチング:複数トークンのリストに同時に現れるページをより関連性が高いと判定。
最近はベクトル検索(MuVerAなど)も使われていますが、本質はキーワードと意味の距離を測る仕組みで、従来のポスティングリストと考え方は似ています。
しかし、現在のGoogleのランキングシステムは、これより遥かに複雑です。初期マッチングが完了した後、Googleは最終的な順位を決定するために、さらに多くの「再ランキング要因(re-ranking factors)」を導入します。セッションでは、そのうちのいくつかを挙げました。
- ユーザーの言語と位置情報:どれだけ優れたコンテンツでも、言語が異なればランキングが下がる可能性があります。
- ブラウザの言語設定:同じ検索語でも、ユーザー環境によって結果が微調整されます。
- コンテンツの品質(Quality):非常に高品質で権威性のあるページは、言語が合致しなくても例外的にそれを上位に表示することがあります。
最後に、「最適化の焦点は“ユーザー”にある。ドキュメントやキーワードに固執するのではない。2000年代のキーワード詰め込みに戻ってはいけない。」この言葉は、この日一日の「品質」というテーマに対する、最高の序文となりました。
⚡ライトニングセッション:品質の多角的な側面(10:40)
このライトニングセッションでは、3人の専門家がそれぞれ異なる立場から「品質」の多面的な側面を掘り下げました。
1. 目に見えない脅威: サイト内検索がSEOを蝕むとき

技術的に高度なこの講演では、表面化しにくいが極めて危険なSEOの脅威、サイト内検索スパム(Site Search Spam)が取り上げられました。これは中国語圏で「検索留痕(検索の痕跡を残す)」とも呼ばれる手法です。
中国や韓国のスパム業者が、サイト内検索機能を悪用し、ギャンブルやアダルトといった違法キーワードを混入させた大量の動的ページを生成。これらがGoogleにインデックスされることで、正規サイト全体の評価が低下してしまうのです。
この攻撃が成功する原因は、通常、サイトに以下のような技術的な脆弱性が存在するためです。
- サイト内検索の結果ページが公開されており、Googlebotがクロール・インデックスできる状態になっている。
- URLとタイトルに、スパムキーワードが表示されてしまう。
- 検索結果がゼロでもHTTPステータスが「200 OK」で返され、正常ページと誤認される。
- 検索クエリと無関係な内容でもシステムが受け入れてしまう。
攻撃の流れはシンプルです。
- 攻撃者がサイト内検索機能がインデックス可能なサイトを発見する。
- スクリプトでスパムクエリを含む動的URLを大量生成。
- 生成したURLをクロール誘導用のリンク集に投入し、Googlebotに素早くクロールさせる
- 誤ってインデックスされれば、その低品質ページ群は「サイトの一部」と見なされ、評価を大きく損なう
これは単なるスパムではなく、深刻なSEOセキュリティリスク です。無害に見えるサイト内検索機能が、サイト全体のSEOを破壊することになり得ます。
登壇者はいくつかの対策を提示しましたが、単一の完璧な解決策はなく、サイトの状況に応じて組み合わせる必要があると強調しました。
- 技術的なブロック:reCAPTCHAの導入、検索機能の利用にログインを要求する。
- クローラー抑制:robots.txtで検索結果ページをブロック、noindexタグを付与、クエリの長さに応じた動的noindex設定など。
対策として、GSCの大量データエクスポート機能をGoogle BigQueryと連携させ、大規模に異常URLを検知・分析するアプローチが推奨されました。少なくとも3か月以上の継続監視が必要とのことです。
2. AIを活用し、データに基づいたE-E-A-Tコンテンツを作成する

インドネシア出身のSEO兼ストーリーテリングコンサルタントであるNabila氏は、全く異なる人文学的な視点から、高品質なコンテンツの本質に迫りました。彼女は、高品質コンテンツの核心は「人」にあり、AI時代であってもその本質は変わらないと主張。
E-E-A-Tに対応する4つのコンテンツ制作原則を提唱しました。
- 独自の視点(Novel point of view):情報を寄せ集めるのではなく、誰も語っていない新しい角度から切り込むこと。
- 感情的なつながり(Emotional):ストーリーで読者の感情に訴えかけ、彼らの真のペインポイントを解決することで、深い共感を呼ぶ。
- データドリブン(Data driven):感情や視点に加え、専門的な調査・研究や信頼できるデータを組み合わせ、論点に説得力を持たせること。
- 記憶に残る工夫(Memorable):露出がゴールではない。読者に覚えてもらうことこそが重要。強烈なオープニングやビジュアル、動画などを駆使し、読者の記憶に刻むこと。
さらに実践的なテクニックとして、彼女は 「AIに読者を模擬させる」 方法を紹介しました。たとえば、AIに対して「特定の悩みを持つ読者として振る舞ってください」と具体的に指示することで、よりユーザー視点に立った発想や切り口を得られるというものです。
TEDトークのように人の心を動かすコンテンツは、生まれ持った才能ではなく、どれだけオーディエンスを理解できるか にかかっています。
3. 生成AIコンテンツはSEOで通用するのか?ランキング&ユーザー行動の実験結果

3人目の登壇者、Rio氏は「生成AIはコンテンツ制作の未来だ」と断言しつつも、そのSEO効果に対する業界の疑念に、厳密な実験で答えを示しました。「生成AIが書いたコンテンツは、人間が書いたものと同等、あるいはそれ以上のSEOパフォーマンスとユーザーエンゲージメントを達成できるのか?」
実験では、コンテンツを3つのグループに分けて比較しました。
- 人間による執筆:その分野の専門家が執筆。
- ChatGPT(未調整):何のチューニングもしていないAIの出力。
- 最適化済みGPT-4:社内データやブランドのトーンを学習させ、最適化されたAIの出力。
全てのコンテンツは、厳格な4ステップのプロセスを経て制作されました。
- テーマと検索意図の定義
- ニーズ調査(検索結果と自社APIから関連質問を抽出)
- コンテンツ構成案の作成(プロンプトで段落構造を指示)
- 初稿執筆とレビュー(特に「Experience(経験)」シグナルの補強を重視)
最も重要なのは、全てのAI生成コンテンツが人間のレビューを受け、特に「Experience(経験)」に関連するシグナル(実際のケーススタディ、著者情報、引用元など)を補強した点です。また、GA4、Hotjar、GSCなどのツールを使い、ランキングだけでなく「ユーザーエンゲージメント」を多角的に計測しました。
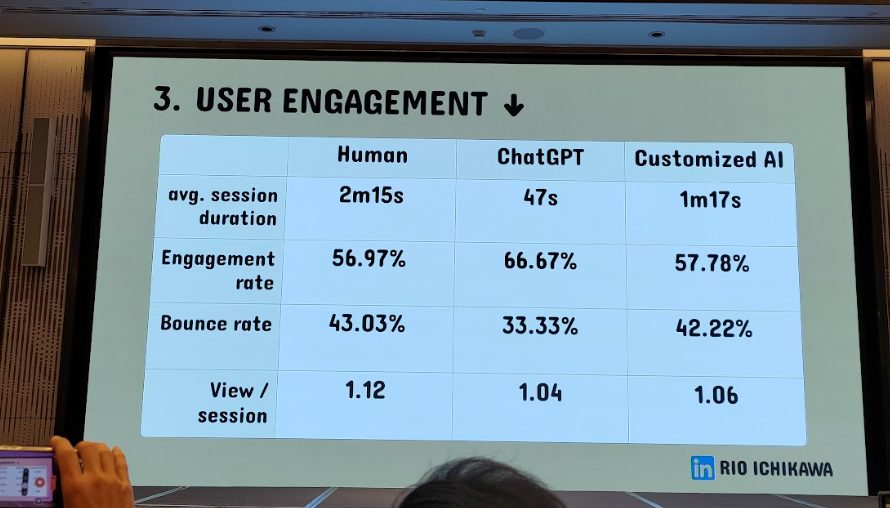
実験結果は驚くべきものでした。
- ChatGPTそのままの記事はやや劣ったものの、最適化されたGPT-4記事は人間執筆とほぼ同等、むしろ一部のエンゲージメント指標では上回った。
- 生成AIは「社内知識+人間の編集プロセス」と組み合わせることで、価値あるコンテンツを大量かつ効率的に生み出せる。ペナルティを受けるどころか、生産性と品質を両立できる可能性がある。
この3つのライトニングセッションは、AI時代のコンテンツ戦略の未来図を描き出しました。これは「AI vs. 人間」のゼロサムゲームではなく、「AI + 人間」の協調的な進化です。
AIはE-E-A-Tにおける「Expertise(専門性)」と「Authoritativeness(権威性)」を処理する強力なツールとなりつつあります(研究データの高速な整理など)。
しかし、「Experience(経験)」と「Trust(信頼性)」という最も重要な2つの要素は、依然として人間にしか提供できない価値です。
最も成功する戦略は、AIを活用して情報処理のスケールを拡大し、人間の専門家を単純作業から解放し、複製不可能な実体験と感情的なつながりの提供に集中させることでしょう。
Googleは「品質」をどう見ているか(11:10)
このセッションではGoogle公式チームが登壇し、SEO業界で長年議論されてきた疑問「Googleは一体どうやって『コンテンツの品質』を定義しているのか?」に真正面から答えました。

まず押さえておくべき二つの誤解
- 404ページ ≠ 低品質:存在しないページや未インデックスのページは「技術的問題」であり、コンテンツ自体の品質とは無関係。
- E-E-A-Tは直接的なランキング要因ではない:E-E-A-Tはあくまで人間の評価者向けのガイドラインであり、アルゴリズムがそのまま参照する「シグナル」ではない。
登壇者は、品質は単一のランキング要因ではなく、Googleのシステムが「コンテンツがユーザーにとって本当に役立つか」を判断するための中核的な「概念」であると強調しました。Googleが高品質なコンテンツを評価する際、以下の側面から考えます。
- ユーザーファーストであるか
- 専門性と深さを備えているか
- コンテンツ自体の価値が高いか
- 表現や構成が洗練されているか
- 検索エンジン向けに作られただけの内容ではないか
公式参考資料:有用で信頼性の高い、ユーザー第一のコンテンツの作成

さらに登壇者は、この抽象的な「品質」という概念を、より具体的で測定可能なシグナルに変換しようとする試みとして、4つの評価指標を提示しました。
- 労力(Effort):コンテンツが、機械的に大量生産されたものではなく、人が実際に手間をかけて創作したか。
- 独自性(Originality):独自の視点・情報・調査を含んでいるか。他サイトの焼き直しではないか。
- 才能やスキル(Talent or skill):専門性や技術力が感じられ、ユーザーが新しい知識を得られるか。
- 正確性(Accuracy):誤りがなく、特に医療・金融などYMYL分野では厳格な正確性を満たしているか。
これはつまり、Googleが重視しているのは「証明可能な投資(demonstrable investment)」を伴うコンテンツだという強いメッセージです。

登壇者が再度強調したのは、E-E-A-Tは直接的なランキング要因ではないものの、Trust(信頼)がすべての品質シグナルの中で最も重要であるということ。
今後コンテンツ制作者が直面する課題は、単に正確な情報を書くことではありません。
「Googleとユーザーに対して、自分がどれだけ労力をかけ、独自性を追求し、専門性を発揮したのかをどう証明するか」。
これは、独自の研究、カスタマイズされた図表、個人的な体験談、そして一歩踏み込んだ、ありきたりでない深い洞察。これらが、コンテンツの差別化における決定的な要因になることを意味しています。
実例で見る「品質」の判断基準
- 低品質の例:テンプレート的な言葉を使い、具体的な視点や独自性のないレビューサイト。
- 高品質の例:ある音楽アルバムに対する個人のレビュー。感情的な体験や背景を詳述し、引用やリンクも提供されており、高い独自性と信頼性を持つ。
- 一次情報の重要性:専門家でなくても、自身の体験に基づいたコンテンツは、信頼性が高く役立つものになりうる。
公式参考資料:品質評価ガイドラインの最新情報: E-A-T に Experience の E を追加
「品質アップデート」とは何か?(11:35)
品質のテーマを引き継ぎ、このセッションではSEO業界で恐れられる「品質アップデート(Quality Updates)」の正体が解説されました。
登壇者によれば、Googleは毎年数千回ものアルゴリズム変更を行っており、その一部は検索結果全体の品質向上を目的としています。(例:動画枠の調整、SERP機能の更新など)

ここでの核心は、品質アップデートは特定のサイトを狙った「ペナルティ」ではなく、検索エコシステム全体の健全性を高めるためのものだということです。
したがって、コアアップデートでトラフィックが影響を受けた場合、罰せられた原因を探すのではなく、基本に立ち返り、ユーザーのニーズにより合致した高品質なコンテンツを作り続けるべきなのです。
公式参考資料:2019 年 8 月の Google コア アップデートについてサイト所有者が知っておくべきこと、検索品質評価者向けガイドラインの更新
検索トラフィック減少の原因を突き止める(13:00)
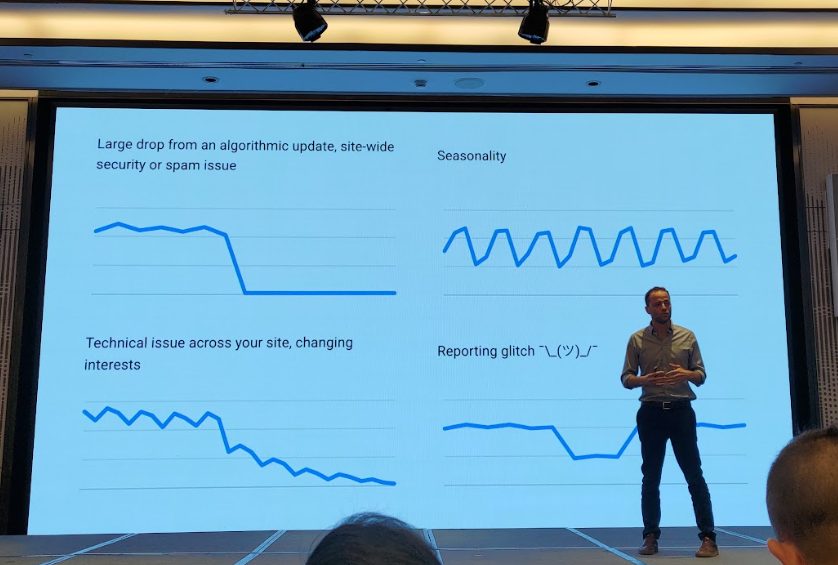
このセッションでは、ウェブサイト運営者必修とも言える、「検索トラフィック減少の診断フレームワーク」が紹介されました。
登壇者は強調します。トラフィック減少は“症状”にすぎない。SEO担当者の役割は医師と同じく、表面的な結果ではなくシステマティックな診断によって「本当の原因」を突き止めることにある、と。
トラフィック減少の典型パターン
- アルゴリズムアップデート:グラフが崖のように急落するケース。通常、コアアップデート、手動ペナルティ、セキュリティ問題などが原因。
- 季節性の変動:業界特有の周期的な増減。旅行業界の繁忙期/閑散期や、週末と平日の差など。
- 技術的な問題:サイトリニューアルやテンプレート更新時の不具合(例:noindexタグの誤設置)で、大量のページがインデックスから消えるなど。
- レポートの異常 ¯\(ツ)/¯:稀ではあるが、発生した場合、通常GSCのグラフ上に公式の注釈が付く。(スライドにあった顔文字が印象的でしたw)
実際の調査ステップ
登壇者は、「まず内部要因、次に外部要因を一つずつ排除する」という考え方に基づいた、厳密な調査フローを提示しました。
- GSC内部レポートの確認:
- ページインデックスレポート:大規模なインデックスの問題がないか確認。
- 手動による対策/セキュリティの問題レポート:最も深刻なサイトレベルの問題を除外。
- パフォーマンスレポートの分析:
- 期間を過去3か月から16か月に広げ、前年同期と比較し、季節要因を除外する。
- 「比較」機能(例:直近3ヶ月 vs その前の3ヶ月)を使い、変化の正確な開始点を特定する。
- 「クエリ」「ページ」「国」などのディメンションを深掘りし、最も影響を受けた箇所を特定する。
- 検索タイプ(ウェブ、画像、動画、ニュース)をチェックし、特定の表示形式のみが影響を受けていないか確認する。
- 業界トレンドとの比較:
- Google Trendsを使い、GSCでトラフィックが最も減少した主要キーワードと、業界全体のトレンドを比較する。このステップは、問題が自社にあるのか、市場全体が縮小しているのかを判断する上で極めて重要。
例:もし業界トレンドが20%減少している中で、自サイトが5%しか減少していなければ、実は市場平均を上回っている。逆に、業界が成長しているのに自サイトが横ばいか減少しているなら、競合に遅れをとっている。 - 定期的に上位5〜10クエリをGoogle Trendsと比較するのが推奨される。
- Google 検索ステータス ダッシュボードの確認:
- 内部調査で問題が見つからない場合、最終手段としてGoogle 検索ステータス ダッシュボードを確認し、その時期に公式なアルゴリズムアップデートが発表されていなかったかチェックする。
このフレームワークにより、SEOにおける流量減少の分析は「当て推量」から「科学的診断」へと進化しました。
これによってSEO担当者は、上司やクライアントに対し、より自信を持って報告できるようになります。
「技術的な問題と季節要因は排除しました。トラフィック減少は業界全体の傾向と一致せず、特定の時期に未公表のアルゴリズム変動と強く相関しています。おそらく、特定の品質問題によって、他社よりも大きな影響を受けた可能性が高いです。」
公式参考資料:Google 検索トラフィックの減少をデバッグする、Google 検索トラフィックの減少を分析する
検索結果はどのようにして生まれるのか?(13:20)
このセッションでは、SERP(検索結果ページ)がどのように生成されるのか、その仕組みが解説されました。
登壇者によると、現代のSERPはもはや「青いリンクが10本並ぶ静的リスト」ではなく、複数のコンポーネントが動的に組み合わされたモザイク的な構造だといいます。
SERP生成の基本プロセス
- クエリ理解(Query Understanding):Googleはまず、自然言語処理・言語モデル・過去のクリック履歴を用いてユーザー意図を推測します。そのうえで、クエリを分類し「情報探索型」「ナビゲーション型」「トランザクション型」、さらには画像・動画・ニュースなど特殊なニーズを含むかどうかを判断します。
例:
- 「fondue recipe」→ ユーザーはレシピを期待していると予測。
- 「durian」→ 画像・栄養・購入など意図が曖昧なため、過去の利用傾向を参考に結果を組み立てる。
- 候補ページの抽出(Candidate Generation):巨大なインデックスから関連ページを抽出。この際、従来のPosting List検索に加え、語義の類似度やベクトル検索も併用して多様な候補を確保します。
- 初期ランキング(Pre-ranking):TF-IDF、BM25、コンテンツの関連性、権威性といった従来の指標に基づき、候補ページを暫定的に順位付けします。この段階では、リッチリザルトなどはまだ考慮されていません。
SERPコンポーネントとリッチリザルト
- 青いリンク(Blue Links):今もなおSERPの主要な要素。
- リッチリザルト:近年Googleが注力。構造化データをもとに情報をカード形式で表示。
- マルチモーダル結果:画像・動画・ニュース・地図・Discoverなどが混在する場合もある。
- 構造化データの重要性:ランキング要因ではないが、SERPでの見栄えを良くし、間接的にCTR向上につながる。
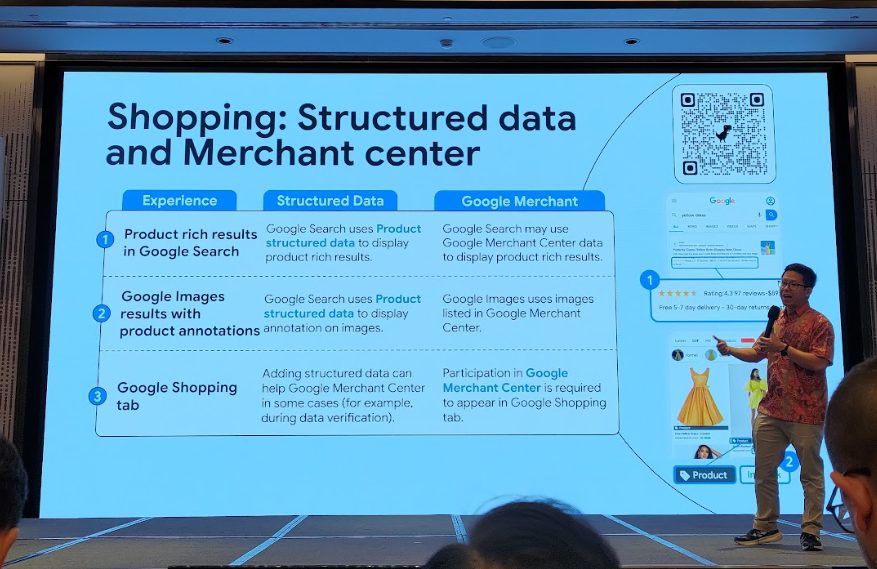
構造化データとGoogle Merchant Centerの違い
Googleショッピングや商品検索において、構造化データとGoogle Merchant Centerはどちらも露出を高めるのに役立ちますが、その役割と利用シーンは異なります。以下に要点をまとめました。
- Google検索のリッチリザルト(Product rich results in Google Search)
- 構造化データ:ページ内のProductマークアップを使い、評価・価格・在庫情報を直接表示
- Google Merchant Center:商品データを参照し、結果に反映される場合もある
- Google画像検索の注釈(Google Images results with product annotations)
- 構造化データ:画像下に製品情報を追加
- Google Merchant Center:登録済みの商品データを引用して表示
- Googleショッピングタブ(Google Shopping tab)
- 構造化データ:単独では掲載されないが、データ検証を補助
- Google Merchant Center:商品情報を完全にアップロードすることが必須。唯一の掲載条件。
| 機能 / 表示場所 | 構造化データ | Google Merchant Center |
| Google検索のリッチリザルト | ページに構造化データ(評価、価格、在庫など)を直接表示する。 | Merchant Centerに登録された商品データが利用され、検索結果に反映される場合もある。 |
| Google画像検索の商品情報 | 構造化データをもとに、画像下に商品情報を付与。 | Merchant Centerに登録済みの商品画像・情報を引用して表示。 |
| Googleショッピング タブ | 単に構造化データを記述するだけでは掲載不可。ただしMerchant Centerでの情報処理に役立つ補助的役割を持つ。 | 商品データを完全にアップロードすることが必須条件。ショッピングタブに表示される唯一の手段。 |

注意点と重要な示唆
- 構造化データは直接的なランキング要因ではない。
- 構造化データを追加しても、リッチリザルトが表示される保証はない。
- 逆に、構造化データがなくても表示されることがある。
- 定期的なメンテナンスが必要。
登壇者は、「SEOにおける思考を『順位』から『露出機会』へと切り替えるべき」と強調しました。
すなわち、これからは「◯位に表示されるか?」ではなく、「SERPのどの枠にどれだけ登場できるか?」 が成果の指標になるのです。
これは、Day1で提唱された「Position(順位)よりもPresence(存在感)」という核心的な概念を改めて裏付けるものです。
SEOの目標は、ターゲットキーワードで利用可能な全てのSERPコンポーネントを特定し、自社のページを、できるだけ多くのコンポーネントの候補となり得る形に最適化していくことなのです。
⚡ライトニングトーク:SERPとあなたのユーザーを理解する(13:40)
このライトニングセッションでは3人のスピーカーが登壇し、SEO戦略を技術的な側面から、データサイエンス、ブランドマーケティング、そしてユーザー心理学のレベルへと引き上げました。
1. Googleの未発表アップデートをデータから検知する方法

Googleが公表しないアルゴリズム更新を、自分たちのデータから検知できるか?」にフォーカス。結論は、待つのではなく自前のデータモデルを構築して変化を察知すべきだと述べ、2つの非常に革新的なカスタム指標を共有しました。
- Canonical URLs in Search: この指標は、「Google検索から実際に流入があったCanonical URLの数を日次で追跡する」ものです。「総インプレッション数」や「総クリック数」とは異なり、特定の人気ページの急激な増減によるノイズを排除できるため、サイト全体がSERPでどの程度幅広く露出しているかを、より正確に把握できます。Canonical URLは、Googleが正規ページとして認識したURLを指し、インデックスやランキングにおける基本単位となります。
実践方法:- First Time To Search (FTTS): この指標は、「新しいコンテンツを公開してから、初めてGoogle検索から流入が発生するまでに要する時間」を測定するものです。
- これにより、Googleが自サイトをクロール・インデックスする効率に変化がないかを効果的に追跡できます。
- さらに、コンテンツの種類ごとにFTTS(First Time To Search)が遅れているかどうかを分析することで、アルゴリズムが特定のコンテンツに対して評価基準や優先度を変更した可能性を推測することも可能です。
実践方法:- 毎日、新しく公開したコンテンツを前日分と突き合わせ、Search Consoleに初めて表示された日付を記録する。
- その日数差を集計し、FTTS全体が遅延する傾向がないかを観察する。
- 必要に応じて、ディレクトリ(フォルダ)単位に分解して分析する。
例:あるタイプのコンテンツでは、FTTSが平均1日から4日へと延びており、Googleがそのカテゴリの処理をアルゴリズム上で調整した、あるいはクロール資源を再配分した可能性が示唆された。
2. 検索ボックスを超えた「現代の混沌としたカスタマージャーニー」におけるSEO

2人目の登壇者は、視点をブランド戦略のレベルに引き上げました。彼は、現代の消費者の購買プロセスは「混沌としている(Chaotic or Messy Middle)」と指摘。ユーザーはもはや直線的なファネルを辿らず、Google、YouTube、Reddit、TikTokなど複数のチャネルを行き来しながら情報を探索し、比較検討します。
こうした背景を踏まえると、SEOの目的は「クリックを獲得すること」から「ユーザーの意思決定に影響を与えること」へシフトすべきです。ブランドはあらゆる接点で、ユーザーの「心のシェア(Share of Mind)」を獲得することが求められます。
- 従来のSEOは順位やクリック率の獲得を重視してきましたが、ブランドが「思い出されるか」「信頼されるか」という本質的な要素は軽視されがちでした。
- 今日の複数チャネルにまたがる意思決定プロセスにおいて、ブランドが競うべきは単なる検索結果での露出ではなく、ユーザーの心に占める割合(シェア・オブ・マインド)です。
- 例えば、「best noise cancelling headphones(ノイズキャンセリングヘッドホンのおすすめ)」という検索順位を奪い合うよりも、ユーザーが直接「Sony WH-1000XM5 review」と検索してくれる状態こそが、ブランド成功の証といえます。
成功のための3要素:
- 発見されやすさ(Findability): Googleだけでなく、あらゆる関連チャネルで存在感を持つこと。動画解説、構造化データの活用など、多面的なコンテンツ展開が求められる。
- ブランド一貫性(Identity): コンテンツ、ビジュアル、トーンを一貫させることで、ユーザーの記憶に残る存在となる。強いブランドメッセージやスタイルを確立し、どの接点でも一貫性を維持することが重要。
- 信頼(Fidelity): 信頼を築き、次回のニーズ発生時に「直接ブランド名で検索」してもらえる状態を目指す。そのためには、継続的な価値提供が不可欠。
結論として、ユーザーが次に検索するとき、あなたのブランド名を入力するかどうか。それこそが未来のSEOの究極のゴールだと述べられました。
3. 現代の検索世界で価値を付加するコンテンツ戦略

3人目の登壇者である Dan 氏は、非常に先進的な概念として 「Experience Forecasting(体験予測)」 を提唱しました。
彼の主張は、AIやマルチモーダル検索の時代において、コンテンツの価値は単なる情報提供にとどまらず、「ユーザーに対し、その製品やサービスが生活にどう影響するのかをあらかじめイメージさせること」 にある、というものです。
- コンテンツは文脈を持ち、前後のつながりを意識すること
- ユーザーの検索行動はもはや直線的ではなく、複雑に入り組んだ旅路となっていること
- 検索動機や利用シーンを予測する「Experience Forecasting」の発想
- コンテンツはオリジナルで、実体験に基づき、実際に役立つものであること
- 「キーワード中心」から「ユーザー中心」へシフトすること
- コンテンツ設計は、興味喚起 → 比較検討 → 最終決定まで、ユーザーの意思決定プロセス全体を網羅すべきこと
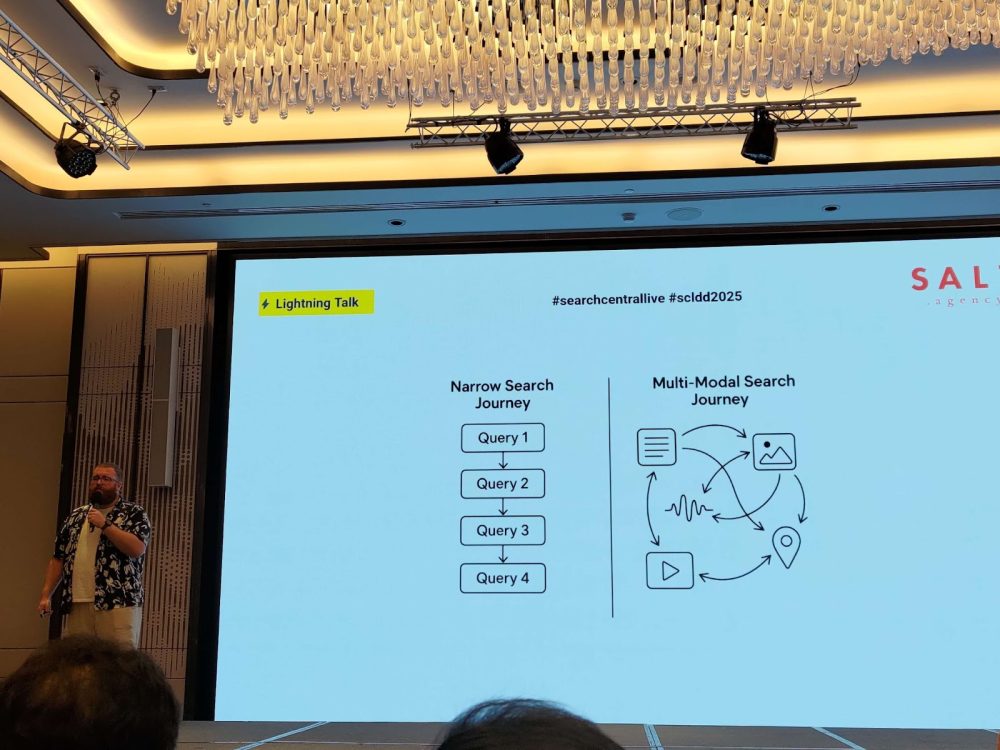
つまり、コンテンツ戦略は「FAQへの回答」や「製品機能の羅列」といった断片的なアプローチから、ストーリー性や利用シーンを描くことで、ユーザーの体験を先取りする内容へと進化する必要があります。
このセッションを含む3つの講演は、SEOの新しいパラダイムを浮き彫りにしました。そこでは、SEO担当者に求められるのは技術力だけではなく、データ分析者の鋭さ、ブランドマーケターの戦略眼、UXデザイナーの共感力まで兼ね備えることだと強調されました。
ポスターセッション :効果的な成功戦略(14:05)

このセッションでは、複数のスピーカーが同時にポスター発表を行い、参加者は興味のあるテーマを選んで自由に質疑応答を行いました。
- B2Bにおけるキーワード選定と最適化戦略
- 社内調整術。CEO/CFO/CMOにSEOの成果をどう伝えるか
- UX視点からのSEOアプローチ
- データベースを活用して「SEOの第二の脳」を構築する方法
大量データエクスポート:Search ConsoleからBigQueryへ(14:50)

この技術セッションでは、Google Search Console(GSC)の強力な機能のひとつ「Bulk Data Export(大量データエクスポート)」 が深掘りされました。
登壇者は「これは単なるデータ量の拡張ではなく、SEOが“観察”から“データサイエンス”へ進化するための根本的な転換点だ」と強調しました。
GSCのデータをBigQueryにエクスポートすることで、サンプリングや集計がされていない生データにアクセスでき、GSCインターフェースの16ヶ月という期間制限を突破して長期的なトレンド分析が可能になります。さらに重要なのは、検索データを他のビジネスデータ(売上、在庫など)やクローラーのデータと関連付けて分析できる点です。
公式参考資料:一括データ エクスポート: Search Console のデータを活用するための優れた新機能
特に重要な、以下のデータテーブルについて紹介しました。
- Table searchdata_site_impression:キーワードとURLの対応を含む最重要テーブル。null値はGoogleが匿名化した検索行動を示す。
- Table ExportLog:レポート生成状況を記録し、データが定期的に出力されているかを確認できる。
この強力な機能を効果的に活用しつつ、コストを抑えるために、登壇者は 2段階の効率化テクニック を共有しました。
1. 計画フェーズ(Plan Phase):
- 使用量制限と予算アラートの設定(Billing Alert): 分析を始める前に、利用量の上限と予算アラートを設定し、コスト超過を防ぐ。
- 事前集計(Pre-aggregate data): よく使う分析軸については、あらかじめデータを集計しておくことで、後続のクエリ処理を高速化。
2.最適化フェーズ(Optimization Phase):
- スキャン範囲の制限(Limit the input scan):クエリ実行時には、可能な限り対象データの範囲を絞り込み、処理負荷を軽減。
- サンプリングの活用(Sample the data): 毎回100%のデータを処理する必要はなく、20%〜70%程度のサンプリングでも十分にトレンド分析が可能。
- 近似関数の使用(Use approximate functions): 絶対的な精度が求められないケースでは、近似値を返す関数を活用することで、処理効率を大幅に向上できる。
この機能によって、「SEOデータアナリスト」や「テクニカルSEOエンジニア」といった役割は、SQLやデータ可視化ツールを駆使して、前述の FTTS(First Time To Search) のようなカスタム監視システムを構築できるようになります。
その結果、従来の Search Console 画面だけでは見えなかった深いインサイトを掘り起こすことが可能になります。
公式参考資料:Search Console の一括データ エクスポートでの BigQuery の効率性に関するヒント
Google TrendsとSearch Consoleによるキーワードリサーチと最適化(15:15)

このセッションは、SEOの日常業務で最も重要な3つのツール、GSC、GA4、Google Trendsに焦点を当て、多くの実務者が抱える長年の疑問を解消しました。
登壇者はまず、よくある2つの誤解を指摘しました。
- 順位だけに注目し、インプレッションやクリック意図を無視する:あるキーワードの順位下落に過敏になりがちだが、そのキーワード自体の検索ボリュームやユーザーのニーズが変化している可能性を見落としている。
- GAとGSCを同じデータとみなす:GSCは「検索行動」(表示されたか、クリックされたか)というサイト流入前のデータ。GA4は「サイト上の行動」(流入後に何をしたか)のデータ。両者は本質的に異なるものであり、混同してはいけない。
公式参考資料:キーワードのプランニング
そして、「なぜGSC、GA4、Google Trendsのデータはいつも一致しないのか?」という問いに対し、明快な説明をしました。
| ツール | 主な焦点 | データソース | 数値が異なる理由 | 最適な利用シーン |
| Google Search Console | 検索インプレッションとクリック | Google検索ログ | Canonical URL単位で集計、ボット流量を除外、非HTML(画像など)も含む、Cookieの影響なし | SEO成果評価、キーワード機会発見、技術的健全性の監視、検索行動の把握 |
| Google Analytics 4 | サイト上のユーザー行動 | サイトのトラッキングコード(JavaScript) | Cookie同意ポリシーや広告ブロッカーの影響を受ける、セッション単位で集計、異なるアトリビューションモデル | サイト内行動分析、コンバージョン経路・エンゲージメント把握、コンテンツや商品の効果測定 |
| Google Trends | 相対的な検索人気度とトレンド | Google検索のサンプルデータ | キーワード/トピック単位で分類、指数化(0〜100)で相対値のみ、ロングテールKWは非表示の場合あり | 市場トレンド把握、季節性分析、テーマ比較、先行的コンテンツ戦略の策定 |
まとめ:AI・検索・そしてすべてを理解する(16:00)
イベントの締めくくりとして、Google公式の代表者が3日間を通じて議論されてきた核心テーマ「AIが検索に与える影響」と「SEOの未来」について、包括的かつ明快な見解を示しました。

1. AI利用の原則と推奨事項
- 効率化のためにAIを賢く使う:
- AIはサイト運営やコンテンツ制作、さらには顧客管理において業務負担を軽減し、生産性を高める力を持っている。
- 責任を持ってAIを利用する:
- AIが事実と異なる情報を生成する「ハルシネーション」を起こすリスクがあるため、特にコンテンツのアウトライン作成時には正確性を必ず人間が確認する必要がある。低品質なAI生成コンテンツの氾濫を助長してはならない。
- Googleにおいて、AIはSEOそのものである:
- Google検索におけるAIの動作原理は従来の検索結果生成と同一であり、SEOの延長線上にあるもの。モバイルファーストインデックスや構造化データと同じく、特別な新概念として扱う必要はない。
公式参考資料:Google 検索の Google AI エクスペリエンスでコンテンツのパフォーマンスを高めるための主な方法
2. Google公式代表者の発言要旨
- AI Overviewは検索の新たな入口:
- 「AI Overviewは検索の代替物ではない。それは新しい入口であり、新しい能力だ。」
- まだ初期段階にある:
- 「AI活用は現在も試行錯誤のフェーズであり、段階的に拡大しながら調整を続けている。。」
- AI Overviewの表示条件は非公開:
- どのような条件下でAI Overviewが出現するかは明らかにされておらず、Google内で継続的に改善中。
- AIの裏側の仕組み:
- 検索のインデックス構造は従来と同じ。検索時には単一のモデルではなく、クエリに応じた プロンプトを基に複数モジュールが協働して結果を生成している。
公式参考資料:AI 生成コンテンツに関する Google 検索のガイダンス
3. SEOの核心的価値と未来
- SEOの本質は変わらない:
- 「結局のところ、重要なのは、役に立ち、関連性があり、信頼できるコンテンツであること。この点は何も変わっていない。」
- 透明性、公平性、引用(Citation)の問題:
- 「引用や流量配分に関する制作者の懸念をGoogleは認識しており、出典表示や透明性の改善を進める」
❓Q&Aセッション:現場の疑問にGoogle担当者が回答!
イベント最後のQ&Aセッションは、参加者がGoogleチームに鋭い質問を投げかけ、活発な議論が展開されました。
Q1|大手サイトが常に優位に見えます。小規模サイトにチャンスはありますか?
A:大手サイトの「権威性」は、長期的に積み上げられた「信頼」であり、確かに優位性はあります。しかし、小規模サイトの活路は「専門領域への集中」と「差別化」、そして複数チャネルからの流入確保にあります。特定の領域で専門性を証明するための強力な証拠を示すことが重要です。
Q2|GSCがAIO(AI Overview)のデータを提供しない中で、SEO担当者はどう効果を測定すればよい?
A:AIO専用データをGSCで切り分ける必要はないと考えています。根本の評価基準は従来と同じ「コンテンツ品質」です。GSCとGA4を連携させ、Googleオーガニック流入後の着地ページや行動変化を観察することを推奨します。
Q3|今後、GSCで「かこって検索(Circle to Search)」のデータは提供される?
A:現時点でその計画はありません。Google内部ではこれらの検索形式を標準クエリに変換しており、GSCに表示される可能性はありますが、特別なラベルが付くことはないでしょう。
なぜなら、たとえデータを提供してもサイト管理者が取れる最適化アクションが限られるためです。Googleは実際に改善に役立つデータ提供を重視しています。
Q4|AIOに広告は導入されるのか?
A:私たちは検索チームであり、広告に関する具体的な計画は分かりません。
Q5|AI生成コンテンツの増加で「低品質な学習データ」問題が深刻化するのでは?人間の書くコンテンツに競争力は残りますか?
A:有用で高品質なコンテンツであれば、生成方法にかかわらず受け入れられます。AI補助コンテンツであっても、人間による編集が加わっているかどうかが品質判断の重要な基準です。
Q6|GoogleはE-E-A-Tを体系的に数値化しているのか?特に“労力(Effort)”はどう測る?
A:E-E-A-Tは評価のフレームワークであって、直接的なランキング要因ではありません。「E-E-A-Tスコア」のようなものは存在せず、労力(Effort)についても単一の指標はありません。システムが数百のシグナルを総合的に評価しています。
Q7|Cloudflareの新しいクローラ管理機能はSEOに影響する?
A:サイト運営者がサーバーリソースを効率的に管理しつつ、Googlebotが価値あるコンテンツを取得できるようにするツールは、ウェブ全体のエコシステムにとって有益です。
Q8|自サイトがAIOで引用されたが、通常のSERPでは2ページ目にある。この場合「AIフレンドリーだがSEOに弱い」ページと考えるべき?
A:これは品質ではなく「関連性」の問題です。AIOに引用されるということは、そのページが特定の質問に対し、事実に基づいた的確な情報を提供している証拠です。ただし、通常のSERPで上位表示を狙うには、包括性や権威性の強化が必要です。
Q9|Googleは著者の信頼性をどう判断する?著者ページ以外にLinkedInなど外部情報も参照する?
A:はい。公開されているあらゆる情報を参照し、その人物や組織の専門性・権威性を理解する材料としています。
awooの考察と今後の展望
3日間のセッションを通じて得られた情報量は膨大でしたが、その根底に流れる核心思想はむしろ一層鮮明になりました。もしAIの波がSEO業界に一時的な迷いをもたらしていたとすれば、今回のDeep Diveイベントは、Googleが提示した最も権威ある「安心材料」であり「ロードマップ」だといえるでしょう。
私たちの考察では、GoogleはSEOに対して明確な「人間中心へのシフト」を促しています。特に3日目の議論がそれを強調していました。「ユーザーの検索意図理解」における同義語・同階層語システムの進化、「品質」の定義に新たに加わった 労力(Effort) や 独自性(Originality)といった評価軸、そしてライトニングセッションで繰り返し語られた「体験予測(Experience Forecasting)」や「混沌としたカスタマージャーニー」。これらすべてのシグナルが示すのは、未来のSEOが人を理解し、人を動かし、長期的な信頼を築くための競争になるということです。技術的抜け穴やキーワードの羅列に依存する旧来型の手法は、完全に淘汰されていくでしょう。
同時に、私たちは「SEOデータサイエンティスト」という新しい役割の台頭も確認しました。検索トラフィック減少を診断する厳密なフレームワーク、Search Consoleの大規模データエクスポートの高度活用、未発表アルゴリズム更新を検知する独自指標の導入。こうした動きは、SEOが「職人的スキル」から「科学的アプローチ」へと進化していることを物語っています。今後勝ち残るのは、ブランド・コンテンツ・ユーザー心理を理解すると同時に、データを操りモデルを構築し、そこから深い洞察を導けるチームです。
結論として、AIはSEOを簡単にするどころか、実務者に求められる総合的な能力のレベルを前例のないほど引き上げました。AIはSEO業界を成熟させ、ビジネスの本質へと回帰させています。
すなわち、信頼されるブランドを築き、代替不可能な価値体験を創造し、その全てを科学的な手法で測定・最適化すること。この道は挑戦的ですが、より確かな道でもあります。
Search Central Live Deep Dive 2025 の3日間にわたるイベントは、ここで幕を閉じました。
これは単なる情報量の多いカンファレンスにとどまらず、世界中のトップクラスの検索専門家と思想を交わし、議論を深める貴重な機会でした。
awooチームは今回の学びを引き続き咀嚼・吸収し、クライアントに実質的な成長をもたらす戦略とアクションへと転化してまいります。
検索の世界は日々変化を続けていますが、卓越を追求し、ユーザーに価値を提供するという初心は決して変わりません。
サイト流量の成長に関する課題やニーズ、あるいは AI SEO/LLMOサービス について詳しく知りたい方は、ぜひお気軽にご相談ください。awooの専門コンサルタントがご連絡差し上げます。
🔗他の日のレポートはこちら
◀️ Day1・Day2のテーマ:
- SEOの時代は終わった?Google公式イベントで語られた、AI検索時代の新たなSEO戦略【Search Central Live Deep Dive Day1 レポート】
- インデックスが勝敗を分ける! テクニカルSEO×JavaScript×多言語サイト戦略 完全ガイド【Search Central Live Deep Dive Day2 レポート】
▎関連記事:專業 SEO 公司如何挑選?4大挑選原則讓你一次搞懂(台湾ブログ)
▎関連記事:【2025最新版】SEO是什麼? SEO怎麼做? SEO搜尋引擎排名優化一次搞懂(台湾ブログ)


