Search Central Live Deep Dive 2025 現場直擊!
awoo 團隊現身泰國曼谷,參加亞太地區首度舉辦的 Search Central Live Deep Dive!這場為期三天的技術研討會,匯聚來自各地的搜尋專家與開發者,共同深入探索 Google 搜尋引擎的底層運作、AI 結合搜尋的最新應用、內容策略與技術 SEO 等重要議題。
經過了 Day 1 對 AI 時代宏觀策略的探討,以及 Day 2 對索引與技術細節的深入剖析,會議終於來到最關鍵的第三天。今天的議程將所有線索匯集,聚焦在 SEO 的終極目標:Google 究竟如何判斷內容的「品質」?搜尋結果頁面(SERP)是如何誕生的?面對流量波動,我們又該如何運用數據進行診斷與優化?
💡 如果你還沒看過 Day1 的精彩摘要:【Search Central Live Deep Dive】Day1:SEO is Dead?AI 搜尋時代的 SEO 新解讀!|awoo 活動實記
💡 這裡也有 Day2 的精彩摘要:【Search Central Live Deep Dive】Day2:索引才是王道!技術 SEO × JavaScript × 多語系策略全攻略|awoo 活動實記
建議可以先看第一篇文章,我們整理了 AI 搜尋時代的新 SEO 觀念與實戰策略!本系列文章將依照每日主題,整理 awoo 第一手觀察與重點筆記。今天是第 3 天,主題聚焦在:品質與排名解密!從使用者意圖到 AI 時代的 SEO 新策略
Search Central Live 是什麼?
Search Central Live 是 Google 搜尋中心團隊主辦的實體活動,專為網站經營者、開發人員與 SEO 專家設計。而 Search Central Live Deep Dive 則是「升級版」的三天進階研討會,內容更廣、時間更長,專為想深入理解搜尋背後機制的與會者而設。這場活動最大的特色,就是從原本的半天或幾小時,延伸為三天完整學習行程,活動的亮點包含:
- Google 官方團隊與社群專家的深度演講
- 真實案例分享 × 技術實作工作坊
- Search Console、Google Trends 等工具的應用教學
- 豐富的現場互動與跨國交流機會
對於關注搜尋技術與自然流量成長的 awoo 團隊來說,這是與全球 SEO 最前線同步的寶貴機會!awoo 實際參與本次活動,以下為我們從現場帶回的第一手觀察與筆記整理。
Search Central Live Deep Dive 第 3 天主題摘要
- 品質是核心,但 E-E-A-T 不是直接排名因子: Google 強調內容品質的重要性,並提出 Effort、Originality、Talent、Accuracy 四大評估指標,但重申 E-E-A-T 本身是評分者指南,而非演算法中的直接信號。
- 使用者意圖與混沌旅程的再定義:SEO 策略需超越關鍵字,轉向預測使用者體驗(Experience Forecasting)與在多渠道的「混沌旅程」中建立品牌忠誠度。
- Site Search Spam 的新威脅:揭露「搜尋留痕」這種新型攻擊,並提供偵測與防禦的實戰策略,凸顯技術 SEO 在網站安全中的重要性。
- 數據驅動的偵錯與優化:結合 GSC、GA4 與 Google Trends 進行流量下降偵錯與關鍵字研究,並詳解 GSC 大量資料匯出的進階應用。
今日主題與逐場精華筆記(依時間軸整理)
第三天開場:歡迎來到搜尋展現與排名主題日!(10:15)
第三天的開場充滿期待,氣氛與前兩日截然不同。如果說前兩天是打地基、蓋鋼骨,今天就是決定建築外觀與內部裝潢的關鍵時刻。主持人以輕鬆的語氣歡迎大家來到「搜尋展現與排名主題日」,預告今天的內容將直搗黃龍,揭開搜尋結果頁面(SERP)背後的神秘面紗。

理解使用者的查詢(10:25)
這場演講從搜尋引擎運作的最源頭——「理解使用者查詢」開始,深入解析了 Google 如何將一串看似雜亂的文字,轉化為精準的意圖判斷。
Google 如何理解及處理關鍵字
當你在搜尋框輸入「曼谷炸雞 推薦」時,Google 內部正進行一場複雜的「翻譯」工作,把查詢需求轉化為它能理解的指令。
- 詞元切分(Segmentation): 將查詢語句拆解成最小的語意單位。例如,「曼谷炸雞 推薦」這句話,會被切分為數個詞元。
- 詞彙清理(Cleaning up): 移除不影響核心語意的贅字。
- 實體識別(Recognize the Entity): 辨識出查詢中的關鍵角色,如品牌、地點、人物等。例如「曼谷」是地點,「炸雞」是食物類型。
- 查詢擴展(Expansion): 根據上下文擴展查詢,以涵蓋更多相關結果。
- 同義詞系統(Synonyms System): 這是最關鍵的一步。系統會根據上下文,將詞元匹配到對應的同義詞。例如,在「fried chicken place in bangkok」這個查詢中,「place」會被理解為「location」或「restaurant」,而「bangkok」會被對應到「bkk」。不僅如此,系統還能找到「同級詞」(siblings),例如當使用者搜尋「canon vs nikon」,系統知道這是在比較兩個相機品牌。

這個流程意味著,Google 早已超越了單純的字串匹配。它理解的是概念與實體之間的關係。當使用者搜尋「最推薦的單眼相機」時,即使沒有明確提及,Google 的系統也已經將 Canon 和 Nikon 視為這個查詢下的隱含競爭者。因此,做內容時要換位思考,必須具備「概念上的競爭者意識」,主動滿足使用者潛在的「比較心態」。
現場也針對這點進行了問答:
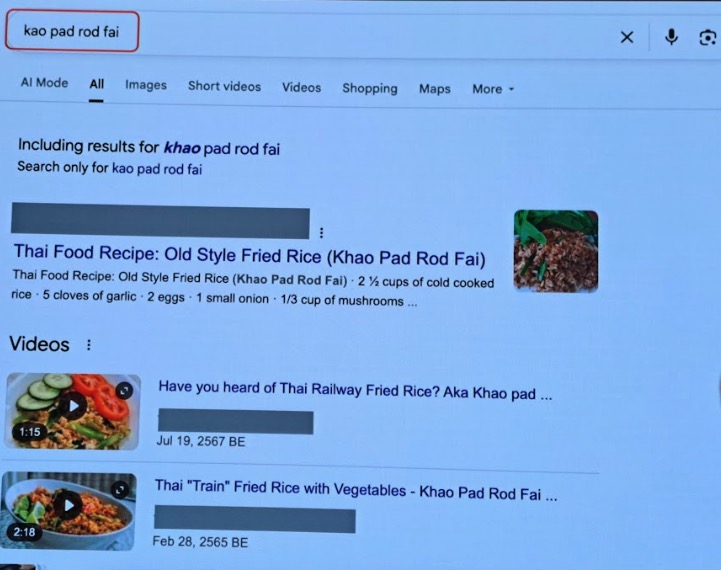
Q|如果用英文查詢非英文字詞,Google 有辦法辨識嗎?
A:看情況。像 pad thai 這種全球知名的字詞,就算拼錯一點也能找到;但對於較冷門的 kao pad rod fai(泰式火車炒飯),打錯字它可能就需要猜測並給你建議。同樣地,系統有時也分不清「湯包」和「小籠包」這類在地詞彙的差別。
從關鍵字匹配到多因子排序
演講者接著回顧了 2000 年代的搜尋理論,當時的 SEO 僅僅是將關鍵字進行詞元化(Tokenization),然後計算其在網頁中出現的頻率。
從技術角度來看,這個基本運作流程包含:
- Tokenization(詞元切分): Google 首先會將使用者查詢切分為詞元(tokens),例如將 “cheap hotel Tokyo” 拆解成三個詞元。這是理解搜尋意圖的第一步。
- Posting List(發布清單): 每個詞元會對應到一份「posting list」,也就是所有包含該詞的文件清單,例如 “Tokyo” 對應到一連串 URL。
- 計數與初步匹配: 若一個文件同時出現在多個詞元的 posting list 中,它會被視為更可能相關,例如某一個 URL 同時出現在 “cheap”、 “hotel”、與 “Tokyo” 的三個 posting list 中,它會初步取得更高的相關性評分。
關於向量檢索的補充說明: 雖然傳統是使用 posting list 檢索,也有人問到 Google 是否使用向量檢索(如 MuVerA)。演講者說即便使用向量,檢索邏輯本質仍然是比較語義距離,和 posting list 類似,只是從二維匹配轉成向量空間的距離度量。
但現在 Google 的排名系統,遠比這複雜。完成初步匹配後,Google 會引入更多「再排序因子」(re-ranking factors)來決定最終排名,講者列舉了其中幾個關鍵因子:
- 使用者語言與地理位置: 即使一個網頁內容再好,如果語言不對,排名也可能被降低。Google 會根據使用者的地點和語言偏好,提供最貼近的結果。
- 瀏覽器語系設定: Google 會根據你的裝置語言(browser interface language)來做微調,這代表搜尋體驗是個人化的,即使查詢語言一致,不同用戶可能看到不同結果。
- 內容品質(Quality): 有時候,一篇內容的品質極高、非常權威,就算語言不完全符合,Google 也可能破格錄取,把它排在前面。
演講者最後強調,優化的重點應該集中在使用者身上,而不是過度專注於文件或關鍵字。他用一句幽默的警告作結:「不要回到 2000 年,堆疊關鍵字早就不管用了。」這句話為接下來一整天的「品質」議題,下了最好的註解。
⚡Lightning Session F:品質的各個面向(10:40)
這場閃電講(Lightning Session)由三位來自不同領域的專家,從截然不同的角度探討了「品質」的多元面向。
1. Invisible Threads: How site searches can harm SEO

這場技術性極高的演講,揭露了一種隱蔽卻極具破壞力的 SEO 威脅:Site Search Spam(站內搜尋垃圾內容),在中文圈又被稱為「搜尋留痕」。
講者指出,這是由來自中國、韓國等地的垃圾內容製作者主導,利用網站自身的搜尋功能,動態生成大量夾帶非法關鍵詞(如博弈、情色內容)的頁面,藉此竊取網站的 SEO 權重。這種攻擊之所以能得逞,通常是因為網站存在以下技術漏洞:
- 站內搜尋結果頁面是公開的,且可被 Google 爬蟲抓取與索引。
- URL 與 Title 能顯示垃圾內容的詞彙。
- 即使搜尋沒有任何結果,頁面依然回傳 200 OK 的 HTTP 狀態碼,讓 Google 誤以為是正常頁面。
- 結果內容對應無關的 query,卻仍被搜尋系統接納
垃圾內容的攻擊流程是:
- 垃圾內容製作者發現某網站支援站內搜尋且開放索引
- 利用腳本大量生成帶有垃圾 query 的動態 URL
- 將這些 URL 放入「蜘蛛池」(zhizhu chi)中,誘導 Googlebot 快速爬取。
- 一旦 Google 漏判並將這些頁面納入索引,網站的整體品質評分就會受到嚴重拖累,因為在 Google 眼中,這些成千上萬的低品質頁面都是「屬於你網站的一部分」。
這不僅僅是垃圾內容問題,它已經演變成一個嚴峻的「技術 SEO 安全議題」。一個看似無害的站內搜尋功能,若配置不當,就可能成為毀掉整個網站 SEO 的後門。
講者也提供了幾種應對策略,但強調沒有單一的最佳解法,需要根據網站情況組合使用:
- 技術阻擋: 使用 reCAPTCHA 機器人驗證、要求使用者登入才能搜尋。
- 爬蟲指令: 在 robots.txt 中阻擋搜尋結果頁的路徑、對搜尋結果頁加上 noindex 標籤、或根據關鍵字長度動態設定 noindex。
講者建議利用 GSC 的大量資料匯出功能,結合 Google BigQuery,可以大規模地檢測和分析這類異常 URL,並需要長期(至少三個月)觀察處理成效。
2. Crafting AI-Powered Data Driven E-E-A-T Content

Nabila 是一位來自印尼的 SEO 與故事行銷顧問,她從截然不同的人文視角切入,分享如何創造高品質內容。她認為,高品質內容的核心在於「人」,即使在 AI 時代,這個本質也從未改變。她提出了對應 E-E-A-T 的四大內容創作原則:
- 獨特視角(Novel point of view): 別只是整理資訊。真正的好內容,始於一個沒人說過的新鮮角度或獨到見解。
- 情感連結(Emotional):用故事觸動讀者的情緒、解決他們真正的痛點,才能引發深刻共鳴。
- 數據驅動(Data driven): 只有觀點和情感不夠,還需要權威的數據、專家研究或真實案例,為論點打造信任基礎。
- 創造記憶點(Memorable): 曝光不是終點,讓讀者記住你才是。強力的開場、吸睛的圖表、感人的影片,都是創造記憶點的武器。
她分享了一個具啟發性的技巧:「當你無法實際訪談用戶時,就請 AI 模擬你的目標讀者」。透過給予 AI 明確的 Prompt,例如「請扮演一位具有某個痛點的讀者受眾」,可以幫助我們跳脫框架,真正從使用者的需求出發。打造如 TED 演講般觸動人心的內容,靠的從來不是天賦,而是你有多麼理解你的觀眾。
3. Gen AI for SEO content: Results on Ranking & User Engagement

第三位講者 Rio 表示生成式 AI 是內容產出的未來,但業界對它在 SEO 上的實際成效仍有疑慮。他們用一場嚴謹的實驗,驗證業界最大的疑問:「生成式 AI 寫的內容,在 SEO 排名與用戶參與度上是否能媲美甚至超越人工撰寫?」。
實驗設計將內容分為三組進行比較:
- 人工撰寫: 由領域專家親自撰稿。
- 原生 ChatGPT: 未經任何微調的 AI 產出。
- 微調過的 GPT-4: 導入了公司內部資料、品牌語調,並經過優化流程的 AI 產出。
所有內容都經過嚴格的四步流程:
- 主題與意圖確認
- 需求研究(從搜尋結果 + 自建 API 抽取相關問題)
- 建立內容大綱(用提示詞引導段落架構)
- 撰寫初稿與審核(特別強調補強「Experience」信號)
最關鍵的是,所有 AI 產出的內容都必須經過人工審核,並特別補強「Experience」(經驗)相關的信號,例如加入真實案例、作者資訊、引用來源等。同時使用 GA4、Hotjar、GSC 等工具來追蹤「用戶參與度」的多面向訊號,而非只看排名。
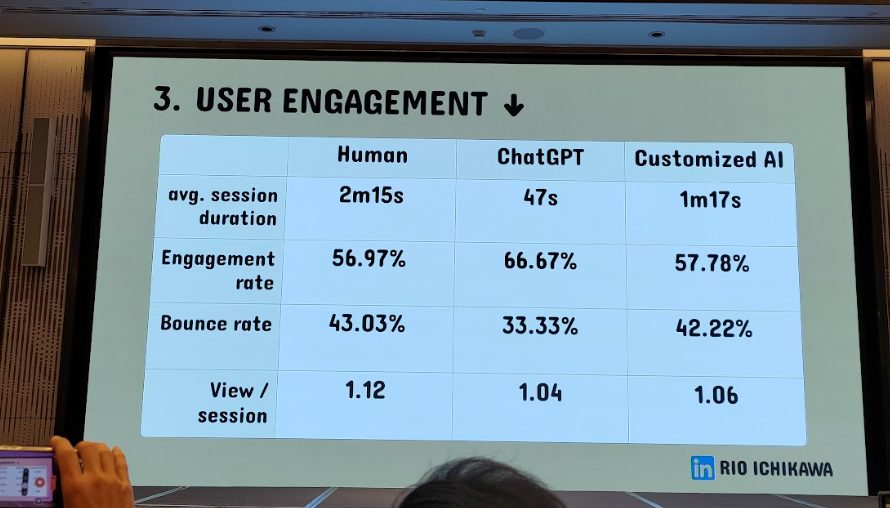
實驗結果令人驚訝:
- 儘管原生 ChatGPT 所寫內容的 SEO 表現略遜,但經過微調與優化的 GPT-4 模型,表現幾乎與人工持平,甚至在某些用戶參與指標上更為出色。
- 生成式 AI 若結合公司內部知識 + 審核機制,能產出真正有價值的內容,不僅不會被降權,還能大幅提升內容生產效率。
這三場閃電講串連起來,描繪出 AI 時代內容策略的未來藍圖:這不是一場「AI vs. 人類」的零和遊戲,而是一場「AI + 人類」的協作進化。AI 正在成為處理 E-E-A-T 中「Expertise」(專業)和「Authoritativeness」(權威)的強大工具(例如快速整理研究資料),但「Experience」(經驗)和「Trust」(信任)這兩個最核心的要素,依然是人類不可取代的價值。最成功的策略,將是利用 AI 擴大資訊處理的規模,同時釋放人類專家的時間,專注於提供無法被複製的真實經驗與情感連結。
Google 如何看待品質(11:10)
這場由 Google 官方主講的議程,直接回應了 SEO 圈長久以來的疑問:Google 到底如何定義「內容品質」?

先釐清兩大迷思:
- 404 頁面 ≠ 低品質:網站上存在錯誤或未被索引的頁面,這通常是「技術問題」,與內容本身的「品質」無關。
- E-E-A-T 不是直接排名因素:它是一份給真人評分員參考的「指導原則」,用來校準演算法,但裡面的項目並非演算法中可以直接操作的排名信號。
講者強調,品質並非單一的排名因子,而是一個核心「概念」,用來指導 Google 的系統去判斷內容對使用者是否真的有幫助。Google 評估高品質內容時,會從以下幾個面向思考:
- 以使用者為優先
- 具備專業與深度
- 內容及品質
- 精良的呈現與製作
- 避免只為討好搜尋引擎
官方參考文件:製作實用、可靠且以使用者為優先的內容

而講者進一步提出來評估內容品質的四個指標,這可以視為 Google 試圖將抽象的「品質」概念,轉化為更具體、可衡量的信號:
- 投入(Effort): 內容是否由人類投入真實的心力創作,而非機器自動化、大量拼湊的結果。
- 原創性(Originality): 內容是否具備獨特的觀點、資訊或研究,而不僅僅是複製或改寫其他網站的內容。
- 才能或技能(Talent or skill): 內容是否展現出創作者的專業才能或高超技巧,讓使用者能從中學到東西。
- 準確性(Accuracy): 內容是否準確無誤,尤其對於 YMYL(Your Money or Your Life)主題,如:醫療、財經等,準確性是絕對的底線。
這背後傳達了一個強烈的信號:Google 正在努力獎勵那些在內容創作上做出可證明投資(demonstrable investment)的網站。

講者也再次重申,E-E-A-T 是給「搜尋品質評分者」參考的指南,並不是演算法中的直接排名因素,但其中的「Trust」(信任)無疑是所有品質信號中最重要的一環。對於創作者來說,未來的挑戰不再只是寫出正確的資訊,而是要思考:「我該如何向 Google 和使用者『證明』我為這篇內容付出的努力、原創性與專業才能?」這意味著,原創研究、客製化圖表、個人案例分享、以及深刻不落俗套的觀點,將成為內容能否脫穎而出的關鍵。
實例說明
- 低品質範例: 評論網站使用模板化語言、無具體觀點或原創性,被判定為低品質。
- 高品質範例: 個人對音樂專輯的評論,詳述情感體驗與背景,並提供引用與連結,具備高度原創與信任性。
- 第一手經驗的重要性: 即使非領域專家,只要基於親身使用也能創造出可信與實用的內容。
官方參考文件:品質評分者指南的最新資訊:在 E-A-T 中增加了 E (Experience)
什麼是品質更新?(11:35)
延續品質的主題,這場議程解釋了大家聞之色變的「品質更新」(Quality Updates)究竟是什麼。講者說明,Google 每年都會進行數千次的演算法變更,其中一部分就是針對提升整體搜尋結果品質的更新,例如調整內容格式(如影片版位)、更新 SERP 功能、或處理特定類型的內容問題。

核心觀點是:品質更新並非針對單一網站的懲罰,而是為了提升整體搜尋生態系的健康度。因此,當流量受到核心更新影響時,重點不應是尋找被懲罰的原因,而是應該回歸基本面,持續產出更符合使用者需求的高品質內容。
官方參考文件:網站擁有者應瞭解的 Google 2019 年 8 月核心更新、搜尋品質評分者指南更新
偵錯搜尋流量下降問題(13:00)
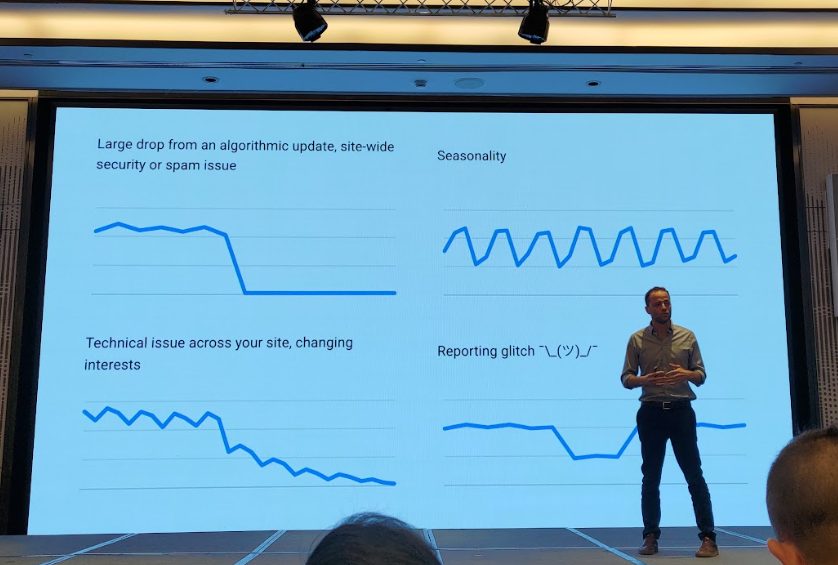
這場演講提供了一套極具價值的「搜尋流量下降偵錯框架」,可說是網站經營者的必修課。講者強調,流量下降是一個「症狀」,而 SEO 專業人員的工作就像醫生,需要透過系統化的診斷,找出真正的「病因」。
流量下降的常見類型
- 演算法更新: 流量圖呈現懸崖式驟降,通常與核心更新、手動處罰或安全問題有關。
- 季節性波動: 呈現規律的週期性起伏,如旅遊業的淡旺季、週末與工作日的流量差異。
- 技術問題: 通常是網站改版或模板更新出錯,例如誤植 noindex 標籤導致大量頁面從索引中消失。
- 報表異常¯\(ツ)/¯: 較為罕見,但若發生,GSC 圖表上通常會有官方註記。(講者簡報的顏文字¯\(ツ)/¯很有趣)
實際排查步驟
講者提供了一套嚴謹的排查流程,核心精神在於「先內後外,排除變因」:
- 檢查 GSC 內部報告:
- 頁面索引報告: 確認是否為大規模的索引問題。
- 手動處罰/安全性問題報告: 排除最嚴重的站點層級懲罰。
- 效能報告分析:
- 將時間範圍從最近 3 個月拉長至 16 個月,並與去年同期比較,以排除季節性因素。
- 利用「比較」功能(如前 3 月 vs 後 3 月),找出流量變化的確切起始點。
- 深入分析「查詢字詞」、「頁面」、「國家/地區」等維度,找到受影響最嚴重的部分。
- 檢查搜尋類型(web、image、video、news)以找出是否僅特定版位受影響。
- 與產業趨勢比對:
- 使用 Google Trends,將 GSC 中流量下降最主要的關鍵字與產業整體趨勢進行對照。這一步至關重要,因為它能幫助你判斷問題是出在自身,還是整個市場都在衰退。
例如:若產業趨勢下降 20%,而你的網站只下降 5%,代表你的表現其實優於市場平均。反之,若產業趨勢上升,你卻持平或下降,則代表落後同業。 - 建議定期將前 5~10 個高流量查詢放進 Google Trends 作對比。
- 查看 Google Search Status Dashboard 近況:
- 若內部檢查都找不到問題,最後一步就是查看 Google Search Status Dashboard,確認該時間點是否有官方發布的演算法更新。
這套方法論,將 SEO 的流量偵錯從「猜測」提升到了「科學診斷」的層次。它讓 SEO 人員在面對老闆或客戶時,能更有信心地說:「我已經排除了技術問題和季節性因素,我們的流量下降與產業趨勢不符,且時間點與一次未經官方證實的演算法波動高度吻合,我們很可能因為某某品質問題而受到了不成比例的影響。」
官方參考文件:針對 Google 搜尋流量下滑情形進行偵錯、分析 Google 搜尋流量下滑的原因
搜尋結果如何誕生?(13:20)
這場演講揭開了 SERP 生成的神秘面紗。講者說明,現代的 SERP 不再是靜態的「十大藍色連結」列表,而是一個由多種「元件」動態組裝而成的「拼貼畫」。整個流程大致如下:
- 查詢理解(Query Understanding): Google 首先透過語意分析、語言模型以及歷史點擊行為,推測使用者意圖。再藉由查詢分類判斷是否為資訊型 (informational)、導航型 (navigational)、交易型 (transactional),以及是否涉及圖片、影片、新聞等特殊內容。
範例:
- 「fondue recipe」→ 預測使用者想要食譜內容與步驟。
- 「durian」→ 無法確定是要圖片、營養或購買資訊,需要依賴過往使用者偏好來組合結果。
- 候選結果產生(Candidate Generation): 系統從龐大的索引庫中,找出所有可能相關的「候選頁面」,這個過程混合使用了傳統的 Posting List ,以及語意相似度與向量檢索來補足多樣化結果。
- 初步排序(Pre-ranking): 根據 TF-IDF、BM25、內容相關度、權威性等傳統檢索指標,對候選頁面進行初步的相關性排序,此時尚未考慮複合式搜尋結果或特殊呈現樣態。
SERP 元件與複合式搜尋結果(Rich Results):
- 藍色連結(Blue Links):仍是主要核心沒有改變
- Google 近年的重點:將結構化資料轉換成複合式結果卡片
- 多模態結果:圖片、影片、新聞、地圖(Maps)、Discover 都可能在 SERP 中出現
- 結構化資料的重要性:並非排名因素,但能讓 SERP 呈現形式更吸睛,間接提升 CTR。
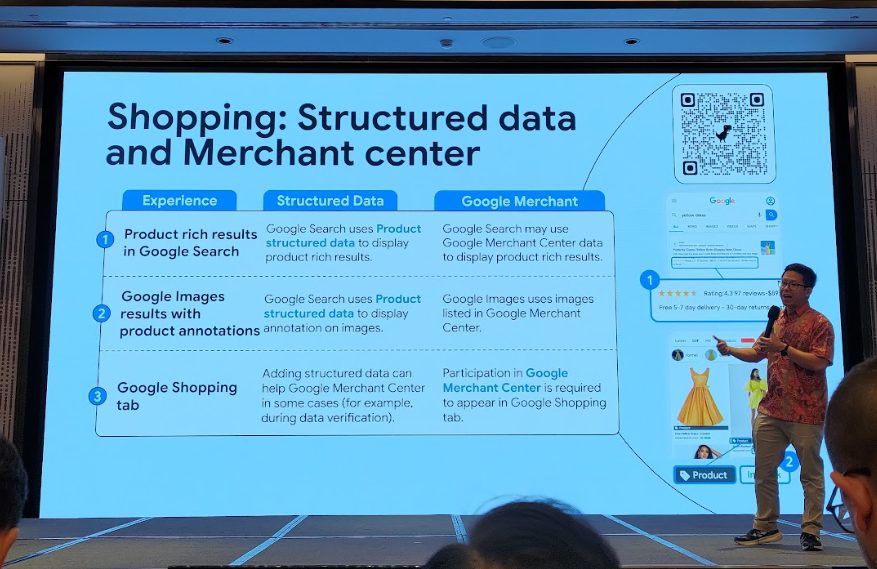
Structured Data 與 Google Merchant Center 差異說明
在 Google 購物與產品搜尋體驗中,Structured Data(結構化資料)與Google Merchant Center 都能協助提升產品在 Google 各項服務上的曝光,不過兩者的角色與應用場景有所不同,簡要整理如下:
- Google 搜尋中的產品複合式搜尋結果(Product rich results in Google Search)
- Structured Data:Google Search 會利用網頁上標記的 Product structured data,直接於搜尋結果顯示產品豐富資訊(如評價、價格、庫存)。
- Google Merchant Center:Google Search 也有機會調用 Merchant Center 的商品資料,來呈現複合式搜尋結果。
- Google 圖片搜尋產品註解(Google Images results with product annotations)
- Structured Data:Google 圖片搜尋會根據頁面上的 Product structured data,直接在圖片下方加註產品資訊。
- Google Merchant Center:Google 圖片則會引用 Merchant Center 已上架的產品圖片與相關資訊進行標註。
- Google Shopping 分頁(Google Shopping tab)
- Structured Data:雖然在部分資料驗證情境下,結構化資料有助於協助 Google Merchant Center 處理資訊,但僅有標記結構化資料,並不能讓產品自動出現在 Google Shopping 分頁。
- Google Merchant Center:必須將商品資訊完整上傳到 Google Merchant Center,才能出現在 Google Shopping 分頁。也就是說,這是參與 Shopping 分頁展示的必要條件。
| 體驗場景 | Structured Data(結構化資料) | Google Merchant Center |
|---|---|---|
| Google 搜尋中的產品複合式搜尋結果 | 直接利用頁面上的 Product structured data,顯示評價、價格、庫存等產品資訊於搜尋結果。 | 也可能調用 Merchant Center 的商品資料來呈現複合式搜尋結果。 |
| Google 圖片搜尋產品註解 | 根據 Product structured data,在 Google 圖片搜尋結果下方顯示產品註解。 | 會引用 Merchant Center 已上架商品圖片與資訊進行標註。 |
| Google Shopping 分頁 | 僅標記結構化資料無法讓產品自動出現在 Shopping 分頁,但有助於 Merchant Center 部分資料驗證。 | 必須將商品資訊完整上傳到 Merchant Center,才能出現在 Shopping 分頁,是唯一必要條件。 |

除此之外,也提及了對於複合式結果的警語:
- 結構化資料不是直接的排名因素
- 加入結構化資料不保證出現複合式結果版位
- 沒有結構化資料,但也有可能出現複合式結果版位
- 需定期且持續的維護
這場演講最重要的啟示是:排名的思維需要徹底轉變。過去我們問「網頁在第幾名?」,現在則要問「我的內容,能在哪些版位上曝光?」一個頁面可能因為內容豐富,在傳統搜尋結果中名列前茅,但若缺少「結構化資料」,就可能放棄了登上複合式搜尋版位的資格。
這也再次印證了 Day 1 提出的「Presence > Position」(存在感大於排名)的核心觀念。SEO 的目標,應該是識別出目標關鍵字所有可用的 SERP 元件,並將頁面優化成能盡可能多地成為這些元件候選者的樣貌。
⚡Lightning Session G:了解搜尋結果頁面和您的使用者(13:40)
這場閃電講(Lightning Session)由三位講者接力,將 SEO 策略從技術層面,提升到了數據科學、品牌行銷與使用者心理學的高度。
1. How to detect un/announced Google update in your data

第一位講者聚焦於:「當 Google 沒有對外公告搜尋演算法更新時,網站經營者能否從自身的資料中推測出是否有變動發生?」,認為與其被動等待 Google 公告演算法更新,不如主動建立數據模型,從自己的資料中找出變動的蛛絲馬跡。他分享了兩個非常創新的自訂指標:
- Canonical URLs in Search: 這個指標追蹤的是「每天實際從 Google 搜尋結果中獲得流量的 Canonical URL 數量」。與「總曝光次數」「總點擊」不同,它排除了單一熱門頁面流量暴增或暴跌的干擾,能更真實地反映網站在 SERP 上的「曝光廣度」是否受到了系統性影響。Canonical URL 代表「Google 已認可的正規頁面」,是索引與排序的重要單位。
相關作法:- 每天統計 Search Console 中有流量的不同 Canonical URL 數。
- 視覺化該指標時間序列圖。
- 將該趨勢與 Google 宣布的更新時間對齊,觀察是否有明顯變動(即使沒公告,也可能出現跌幅)
- 案例:講者展示一段圖表顯示,在某次未公告的時間點,Canonical URLs 突然減少 30%,反映出該網站在 Google SERP 中的曝光面受到了系統性影響。
- First Time To Search (FTTS): 這個指標衡量「新內容上線後,需要多久才能第一次從 Google 獲得搜尋流量」。它可以有效地追蹤 Google 對你網站的抓取和索引效率是否有變化,甚至可以細分到不同內容類型的 FTTS 是否被延後,從而推斷演算法對某些內容的偏好可能發生了改變。
相關作法:- 每日比對前一天新上線的內容,標記其首次出現在 Search Console 中的日期。
- 統計時間差分佈,觀察是否有「FTTS」整體延後的趨勢。
- 可進一步拆解至各資料夾層級。
案例:某些類型內容的 FTTS 從原本平均 1 天延長到 4 天,表示 Google 對該類別內容的處理可能被演算法調整,或抓取資源重新分配。
2. Beyond the Search Box: SEO for Today’s Chaotic Customer Journey

第二位講者將視角拉高到品牌策略層面。他指出,當代的消費者旅程是「混沌的」(Chaotic or Messy Middle),早已不是線性的漏斗模型。使用者會在 Google、YouTube、Reddit、TikTok 等多個渠道之間來回穿梭、探索、比較。
在這樣的背景下,SEO 的目標應該從「引導點擊」轉變為「影響決策」。品牌必須在每一個接觸點上,爭取使用者的「心佔率」。
- 傳統 SEO 追求排名與點擊率,忽略了品牌能否「被想起」或「被信任」的重要性。
- 在多重接觸點的決策過程中,品牌必須爭取「心佔率」而非單一的搜尋曝光。
- 舉例:與其爭奪「best noise cancelling headphones」的搜尋排名,不如讓使用者直接搜尋「Sony WH-1000XM5 review」—這才是品牌成功。
同時講者也提出了成功品牌需要具備的三大關鍵:
- 被找到(Findability): 不只在 Google,在所有相關渠道都要有能見度,多平台內容布局。例如,影片解說、論壇互動、結構化資料。
- 品牌識別(Identity): 內容、視覺、語調保持一致,讓使用者記住你。例如,建立強烈品牌主張與風格,在不同內容場景中保持一致。
- 忠誠度(Fidelity): 建立信任感,讓使用者在下一次有需求時,會主動「直接搜尋你的品牌」。例如,提供持續價值,例如更新指南、客戶故事、專業洞見。
使用者是否願意在下一次直接「搜尋你的品牌」,這才是 SEO 的未來目的。
3. Content that Enables & Adds Value In the Modern Search World

第三位講者 Dan 提出了一個極具前瞻性的概念:「Experience Forecasting(體驗預測)」。他認為,在 AI 與多模態搜尋的時代,內容的價值不再只是提供資訊,而是「幫助使用者預見某個產品或服務將如何影響他們的生活」。
- 內容要具備上下文與前後連結性
- 使用者的搜尋旅程已不再是線性堆疊查詢
- 預測搜尋動機與體驗場景(Experience Forecasting)
- 內容須原創、具經驗性與幫助
- 告別「關鍵字導向」,擁抱「使用者導向」
- 內容設計上應涵蓋整個使用者決策歷程
這意味著內容策略需要告別「關鍵字導向」,全面擁抱經驗與用戶決策的「使用者旅程導向」。內容的規劃應該從回答 FAQ、羅列產品特色,轉向更具體的敘事、場景化描述,涵蓋使用者從產生興趣、研究比較到最終決策的完整心路歷程。
這三場演講串連起來,描繪出一個全新的、更為複雜的 SEO 範式。它要求從業者不僅是技術專家,更需要具備數據分析師的敏銳、品牌行銷長的策略思維,以及使用者體驗設計師的同理心。
海報發表 H:有效的成功策略(14:05)

在這場海報發表環節中,由多位講者同時在場邊分享,與會者可以自由選擇有興趣的主題進行交流與提問。主題包含:
- B2B 關鍵字挑選及優化策略
- 如何向上管理,與 CEO/CFO/CMO 溝通 SEO 成效
- UX 導向的 SEO
- 運用資料庫建立 SEO 第二大腦
大量資料匯出:從 Search Console 到 Bigquery(14:50)

這場技術議程深入探討了 GSC 強大的功能之一:大量資料匯出(Bulk Data Export)。講者強調,這不僅僅是「獲得更多資料」,而是一個根本性的轉變,它讓 SEO 得以從「觀察」走向真正的「數據科學」。
透過將 GSC 資料匯出到 BigQuery,我們可以獲得未經取樣、未經匯總的原始資料,並突破 GSC 介面 16 個月的時間限制,進行長期趨勢分析。更重要的是,可以將搜尋資料與其他業務數據(如銷售額、庫存)或爬蟲資料進行關聯分析。
官方參考文件:大量資料匯出:透過全新且強大的工具存取 Search Console 資料
講者特別介紹了幾個關鍵的資料表(Table):
- Table searchdata_site_impression:這是最核心的資料表,可以直接拉出關鍵字與網址對應的詳細數據。其中,null 值的關鍵字代表的是被 Google 匿名化的探索或檢索行為。
- Table ExportLog:這個資料表可以讓你追蹤報告產生的狀況,確保資料定時送出。
為了有效利用這項強大功能並控制成本,講者分享了兩階段的效率提升技巧:
1. 計畫階段(Plan Phase):
- 限制用量與設定預算警報(Billing Alert): 在開始分析前,就先設定好用量限制與預算警報,避免費用超支。
- 預先彙總資料(Pre-aggregate data): 針對常用的分析維度,可以先將資料進行初步的彙總處理,加快後續查詢速度。
2. 優化階段(Optimization Phase):
- 限制掃描範圍(Limit the input scan): 在下達查詢指令時,盡可能地限縮要掃描的資料範圍。
- 取樣資料(Sample the data): 你不需要每次都分析 100% 的資料,講者提到,通常取樣 20% 至 70% 的資料就足以用來分析趨勢。
- 使用近似函數(Use approximate functions): 在不要求絕對精確的場景下,使用近似值計算函數可以大幅提升查詢效率。
這項功能讓「SEO 數據分析師」或「技術 SEO 工程師」這樣的角色使用 SQL 和數據可視化工具,建立如前面提到的 FTTS 等自訂監控系統,從而發掘出在標準 GSC 介面中無法窺見的深刻洞察。
官方參考文件:Search Console 大量資料匯出作業的 BigQuery 效率提升要訣
透過 Google Trends 和 Search Console 進行關鍵字研究與優化(15:15)

這場議程聚焦於 SEO 日常工作中最重要的三個工具:GSC、GA4 與 Google Trends,並釐清了許多從業者長久以來的困惑。講者首先點出兩個常見的搜尋資料本質誤解:
- 只看排名,不看曝光與點擊意圖: 看到某個關鍵字排名掉了就緊張,卻忽略了這個字背後的搜尋量或使用者需求可能已經改變。
- 將 GA 和 GSC 視為相同資訊: GSC 記錄的是「搜尋行為」(是否被曝光、是否被點擊),是使用者「進入網站前」(會不會來)的數據;GA4 記錄的是「站上行為」(來了之後做了什麼),兩者不能混為一談。
官方參考文件:關鍵字規劃
對於「為什麼 GSC、GA4 和 Google Trends 的數據總是對不起來?」這個經典問題,講者給出了清晰的解釋,我們將其整理成下表,以供參考:
| 工具 | 主要焦點 | 數據來源 | 為何數據不同 | 最佳使用情境 |
|---|---|---|---|---|
| Google Search Console | 搜尋曝光與點擊 | Google 搜尋日誌 | 以 Canonical URL 匯總;排除機器人流量;包含非 HTML 頁面(如圖片);不受 Cookie 影響。 | 評估 SEO 成效、尋找關鍵字機會、監控技術健康度、理解使用者在搜尋時的行為。 |
| Google Analytics 4 | 網站上的使用者行為 | 網站追蹤碼(JavaScript) | 受 Cookie 同意政策、廣告攔截器影響;以「工作階段」為單位;有不同的歸因模型。 | 分析使用者進入網站後的行為、轉換路徑、參與度,衡量內容與產品的實際成效。 |
| Google Trends | 相對搜尋熱度與趨勢 | Google 搜尋取樣數據 | 使用關鍵字/主題來歸類;數據經過指數化(0-100)處理,為相對值而非絕對量;長尾關鍵字可能不顯示。 | 洞察市場趨勢、季節性變化、比較不同主題的熱度、規劃前瞻性的內容策略。 |
總結:人工智慧、搜尋以及理解一切(16:00)
在活動尾聲,Google 官方代表針對三天以來備受關注的核心議題,包含「AI 對搜尋的影響」及「SEO 的未來」,進行了完整而清晰的回應。整體觀點與建議整理如下:

一、AI 使用原則與建議:
- 善用 AI 提升效率:
- AI 能強化工作流程並協助內容製作,包含網站經營與客戶管理,有效降低作業負擔,提升整體工作效率。
- AI 能強化工作流程並協助內容製作,包含網站經營與客戶管理,有效降低作業負擔,提升整體工作效率。
- 負責任地使用 AI:
- 需注意 AI 可能出現幻覺(hallucinate)的狀況,尤其製作內容大綱時,更應審慎確認內容正確性。
- 避免加劇網路上已經氾濫的低品質 AI 內容問題。
- AI 在 Google 中即是 SEO:
- Google 搜尋中的 AI 功能,其實本質與傳統搜尋結果的運作流程完全相同,仍是專注於 SEO。
- 正如過去的行動優先索引(Mobile-first indexing)或結構化資料(Structured data)不需特別對待,AI 搜尋也無需另立新概念或新詞彙。
官方參考文件:在 Google 搜尋的 AI 體驗中,確保內容表現良好的最佳方法
二、Google 官方代表核心發言摘要:
- AI Overview 是搜尋的新入口:
- “AI Overview is not a replacement for search. It’s a new entry point, a new capability.”
- AI Overview 並非取代搜尋,而是開啟探索的起點,是搜尋的新入口。
- 目前仍在早期摸索階段:
- “We’re still in the early days. We’re scaling slowly and learning carefully.”
- Google 正處於謹慎且緩步擴展 AI 應用的階段,逐步測試與學習各種情境。
- AI Overviews 的出現條件尚未公開:
- Google 尚未公布什麼情境或條件會觸發 AI Overviews,團隊仍在不斷調整與精進相關機制。
- AI 背後運作模式:
- AI 的檢索索引流程與傳統的搜尋結果(藍色連結)一致。
- 使用者搜尋時,並非僅呼叫單一模型,而是根據不同查詢情境,自訂特定 Prompt,由多個模組共同協作產出結果。
官方參考文件:Google 搜尋的 AI 產生內容相關指引
三、SEO 的核心價值與未來展望:
- SEO 的核心不變:
- “It’s still all about content that’s helpful, relevant, and trustworthy. That hasn’t changed.”
- 無論技術如何發展,SEO 最根本的核心,仍是提供對使用者有幫助、具相關性與可信的內容。
- 透明度、公平性與引用(Citation)問題:
- “We hear the feedback about citation, and we’re working on more precise attribution.”
- Google 已留意到內容創作者對於引用來源與流量影響的擔憂,並表示會持續優化來源能見度及透明度的設計。
❓QA時間問答精華
活動最後的 Q&A 環節,依然是火花四射,與會者們把握最後機會,向 Google 團隊提出各種尖銳問題。以下是整理後的精華問答:
Q1|大型網站似乎總有權重優勢,那麼小型網站的機會在哪?
A:大型網站的「權重」或「權威性」,本質上是一種長期累積的「信任」。這確實是一種優勢,我們無法否認。對於小型或新興網站來說,機會在於「專注」與「差異化」,並搭配多渠道導流。需要拿出更多、更強的證據,證明你們在某個利基領域的專業性。
Q2|既然 GSC 不提供 AIO(AI Overview)的數據,SEO 人員該如何量化 AIO 的成效?
A:目前,在 GSC 中獨立區隔出 AIO 數據,我們認為並非必要,因為底層的內容品質要求是一致的。建議大家可以將 GSC 與 GA4 串聯,觀察從 Google Organic 來的流量,其著陸頁或使用者行為是否有因為 AIO 的出現而產生變化。
Q3|GSC 未來會提供 Circle to Search 的數據嗎?
A:目前沒有這個計畫。Google 內部將這些搜尋形式轉換成標準查詢,因此可能會在 Search Console 中出現,但並不會特別標示來源為語音或 Circle to Search。這是因為即使提供了數據,網站主能夠採取的優化行動也有限。我們的重點放在提供能讓大家據此改善網站的數據上。
Q4|AIO 近期會開始營利(加入廣告)嗎?
A:我們是搜尋團隊,關於廣告(Ads)的具體計畫我們並不清楚,無法評論。
Q5|隨著 AI 生成內容越來越多,是否會造成「垃圾訓練資料」問題?人類寫的內容還有競爭力嗎?
A:只要內容是有幫助且高品質的,無論其生成方式為何,對我們來說都是可以接受的。因此,高品質的 AI 輔助內容被用於訓練是正常的。目前 AI 生成內容有變多的趨勢,但 Google 內部會依據「是否由人類編輯過」來作為內容品質的核心判斷。
Q6|Google 是否有系統化的方法來衡量 E-E-A-T?如何衡量 “Effort”(投入)?
A:E-E-A-T 不是一個系統或直接的排名因素,它是用來評價內容的一套框架。所以,不存在一個可以量化的「E-E-A-T 分數」。至於 “Effort”,我們沒有單一的指標去衡量它,但系統會綜合評估數百個信號。
Q7|Google 預期 Cloudflare 最新的爬蟲管理功能會造成什麼影響?
A:我們樂見其成。任何能幫助網站主更好地管理其伺服器資源、同時確保 Googlebot 能高效獲取有價值內容的工具,對整個網路生態系都是有益的。
Q8|如果我的網頁被 AIO 引用,但在傳統 SERP 卻排在第二頁,我該如何評價這個網頁的品質?這代表它「AI 友善」但「SEO 不友善」嗎?
A:這個議題跟品質較無關,而跟相關性有關。被 AIO 引用,代表你的頁面上有一個特定的、事實性的資訊片段,對於回答使用者查詢的某個「部分」來說,是極度相關且簡潔的。所以,這不代表你的頁面 SEO 不友善,而是說明它在滿足「片段資訊需求」上表現優異,但若想在藍色連結中獲得頂尖排名,可能還需要在整體的全面性和權威性上繼續努力。
Q9|Google 如何知道一位作者是否可信?除了看作者介紹頁面,會參考 LinkedIn 或其他外部來源嗎?
A:是的,會參考網路上所有關於這位作者或該實體的公開資訊,這些都有助於我們建立對其專業性和權威性的理解。
awoo 的觀察與反思
三天的議程下來,資訊量極其龐大,但貫穿始終的核心思想卻愈發清晰。如果說 AI 的浪潮曾讓整個 SEO 產業感到一絲迷惘,那麼這次的 Deep Dive 活動,無疑是 Google 給出的一份最權威的「定心丸」與「路線圖」。
我們的觀察是,Google 正在引導 SEO 進行一場深刻的「人性化轉向」。第三天的內容尤其凸顯了這一點。從「理解使用者查詢」中的同義詞與同級詞系統,到「品質」定義中新增的 Effort、Originality 等指標,再到閃電講中反覆強調的「體驗預測」與「混沌的消費者旅程」,所有信號都指向一個結論:未來的 SEO,將是一場關於理解人、打動人、並建立長期信任的競賽。 那些只專注於技術漏洞、關鍵字堆砌的舊方法,將被徹底淘汰。
與此同時,我們也看到了「SEO 數據科學家」的崛起。從偵錯流量下降的嚴謹框架,到 GSC 大量資料匯出的進階應用,再到監測未公告更新的自訂指標,都顯示出 SEO 正在從一門「手藝」進化為一門「科學」。未來,能夠勝出的團隊,必然是那些既懂品牌、懂內容、懂心理,又能駕馭數據、建立模型、並從中挖掘深刻洞察的團隊。
總結來說,AI 並沒有讓 SEO 變得更簡單,反而對從業者的綜合能力提出了前所未有的高要求。它正在逼迫整個產業走向成熟,回歸商業的本質:建立一個值得信賴的品牌,創造無可取代的價值體驗,並用科學的方法衡量與優化這一切。這條路雖然更具挑戰,但也更加堅實。
🔗 查看其他篇
◀️ 前兩天主題:
- 【Search Central Live Deep Dive】Day1:SEO is Dead?AI 搜尋時代的 SEO 新解讀!|awoo 活動實記
- 【Search Central Live Deep Dive】Day2:索引才是王道!技術 SEO × JavaScript × 多語系策略全攻略|awoo 活動實記
結語
Search Central Live Deep Dive 2025 為期三天的活動在此畫下句點。這不僅是一場資訊密集的研討會,更是一個與全球頂尖搜尋專家交流思想、碰撞火花的寶貴平台。awoo 團隊將持續消化吸收這次活動的精華,並將其轉化為能為客戶帶來實質成長的策略與行動。搜尋的世界瞬息萬變,但追求卓越、為使用者創造價值的初心不變。
如有任何網站優化相關問題與需求、或想瞭解更多 AI SEO/GEO 服務歡迎填寫表單立即諮詢,將有 awoo 專業顧問與您聯繫。
Contact Us
「*」代表必填欄位