


Search Central Live Deep Dive 2025 現場直擊!
awoo 團隊現身泰國曼谷,參加亞太地區首度舉辦的 Search Central Live Deep Dive!這場為期三天的技術研討會,匯聚來自各地的搜尋專家與開發者,共同深入探索 Google 搜尋引擎的底層運作、AI 結合搜尋的最新應用、內容策略與技術 SEO 等重要議題。
💡 如果你還沒看過 Day1 的精彩摘要:【Search Central Live Deep Dive】Day1:SEO is Dead?AI 搜尋時代的 SEO 新解讀!|awoo 活動實記
建議可以先看第一篇文章,我們整理了 AI 搜尋時代的新 SEO 觀念與實戰策略!本系列文章將依照每日主題,整理 awoo 第一手觀察與重點筆記。今天是第 2 天,主題聚焦在「深入技術 SEO 現場:解構索引流程、破解 JavaScript 陷阱,掌握多語系與內容優化關鍵技術!」
Search Central Live 是什麼?
Search Central Live 是 Google 搜尋中心團隊主辦的實體活動,專為網站經營者、開發人員與 SEO 專家設計。而 Search Central Live Deep Dive 則是「升級版」的三天進階研討會,內容更廣、時間更長,專為想深入理解搜尋背後機制的與會者而設。這場活動最大的特色,就是從原本的半天或幾小時,延伸為三天完整學習行程,活動的亮點包含:
- Google 官方團隊與社群專家的深度演講
- 真實案例分享 × 技術實作工作坊
- Search Console、Google Trends 等工具的應用教學
- 豐富的現場互動與跨國交流機會
對於關注搜尋技術與自然流量成長的 awoo 團隊來說,這是與全球 SEO 最前線同步的寶貴機會!awoo 實際參與本次活動,以下為我們從現場帶回的第一手觀察與筆記整理。
Search Central Live Deep Dive 第 2 天主題摘要
- 索引才是王道,能不能被收錄比排名更重要
- JavaScript 網站並非死路,只要正確處理渲染與連結
- 多語系策略重在 hreflang 與 sitemap 配合
- Google Trends API 正式開放試用申請!
今日主題與逐場精華筆記(依時間軸整理)
第二天開場:歡迎…來到索引日!(10:15)
今天的開場不囉嗦,Google 搜尋團隊一上台就進入快問快答模式!雖然只有短短幾題,但每題都打中技術 SEO 最常遇到的疑慮,今天不只是學理,是真刀真槍的技術交流日!

Q:其他 Chatbot 會遵守 robots.txt 嗎?
A:不一定,Google 不能保證別家怎麼做,但從技術角度來說,robots.txt 本身就是「自願遵守」的協定。
Q:圖片大小會影響檢索預算嗎?
A:不會,Google 的抓取預算是「以頁面為單位」來計算,而非依據每個資源的大小。但若圖片或影片太大,會造成抓取延遲、甚至排程暫停,直到某些大物件下載完成。
Q:Google 是否在抓取效率上偏好響應式(responsive)網站?
A:沒有偏好、也不特別辨別技術選擇。但如果使用 adaptive 或 dynamic rendering,往往會帶來更多 JavaScript、影像延遲與重建渲染成本。
Q:怎麼判斷自己的檢索預算是否用得好?
A:可以去 Search Console 的 Crawl Stats 報表查看兩個指標:
- 實際被抓取的 URL 數量
- 「已找到 – 目前尚未建立索引」(discovered – not crawled)的項目數量。
如果後者偏高,可能代表站內內容太多 Google 檢索不完,或是內容品質太低 Google 不想抓,又或者是有 server/network error 阻礙抓取。
Google 搜尋團隊也補充,目前的索引流程比你想像得更複雜,不只是 bot 爬了就結束,還包含:
- HTML 解析
- JavaScript 渲染
- 重複頁面判定
- 重點內容擷取(Main Content)
- 信號擷取(Canonical、hreflang、meta tag 等)
- 最後才是索引與排名
HTML 如何被「解讀」?Google 怎麼拆解你的網頁(10:25)
這場從根本說明 Googlebot 是怎麼讀懂你網站的。不是你塞了關鍵字、加了內部連結就算完事,而是從 DOM 架構開始,Google 就在分析你網頁的每一層邏輯。Google 的解析方式大致如下:
- <head> → 抓取 title、meta 等中繼資訊
- <body> → 拆解 nav、main content 等內容區塊
講者強調 Main Content 超重要!Google 會試著找出頁面真正的主體內容。你如果沒正確標註,或者主要內容太稀薄、跟其他導覽列/側邊欄的資訊混在一起,可能會讓 Google 判斷失準。爬蟲在這階段會解析的資訊包含:
- canonical 標籤
- hreflang 語言對應
- robots tag
- 各類連結與 JS 資源是否可見
現場也提到 Googlebot 如何根據網址結構與 JS 執行權限,判斷哪些頁面能抓、哪些不能抓。
官方參考文件:適用於 Google 的連結最佳做法

有哪些方法可以控制索引?(10:30)
下一場則進入技術實作,聚焦於「你可以如何告訴 Google:這個不要抓、那個不能收錄」。Google 把整個搜尋流程分成兩階段:
1️⃣ Crawling(能不能被抓/檢索)
靠的是 robots.txt,可以阻擋 Googlebot 抓特定資料夾或資源(如 JS、CSS、圖片)。
2️⃣ Indexing(能不能被收錄/索引)
靠的是 <meta name=”robots”>,可以指定非常多細節規則:
| 指令名稱 | 功能說明 |
|---|---|
| noindex | 不要被索引/收錄 |
| nofollow | 不傳遞連結權重 |
| nosnippet | 在搜尋結果中不顯示文字摘要 |
| data-nosnippet | 在搜尋結果中隱藏特定段落/文字 |
| max-snippet | 限制文字摘要長度(-1 為無限制,0 表示不顯示) |
| max-image-preview | 控制圖片預覽尺寸(none / standard / large) |
| max-video-preview | 控制影片預覽秒數 |
| noimageindex | 不讓圖片被收錄 |
| no-translate | 不提供翻譯版本,避免翻譯失真 |
| unavailable_after | 在特定時間後,於搜尋結果中移除頁面 |
現場提問
Q:可以用 JavaScript 加上 meta robots tag 嗎?
A:可以,但會花較長時間,因為需要等 JS 渲染完成後才能解析。
官方參考文件:Google 支援的 meta 標記和屬性
值得一提的是,Google 說明中提到 nofollow 是為了「to prevent passing on ranking credit」,也就是不傳遞權重。換句話說,傳說中的 link juice 真的是存在的!SEO 界討論多年的概念,這裡等於間接獲得了官方背書。
⚡Lightning Session C:渲染與 JavaScript
一開場就提到:就連Gary的網站也用了不少 JavaScript!所以「想辦法讓 JS 產生的內容能被爬蟲看見」,就是這場 Session 的核心。講者們用三個精彩實例,帶我們一口氣看懂 JS 與 SEO 的微妙關係:
1️⃣ 案例一:讓內容 SEO 與技術 SEO 一起合作
前陣子 SEO 界吵得很兇的:技術 SEO 重要?還是內容為王?
講者認為兩者不能分開看,而是要相輔相成。舉例來說,電商網站若只顧著寫一堆長文部落格,Google 可能會判斷這個網站「非交易導向」,反而拖累自然流量表現。一個成功的 SEO 策略,應從網站狀態診斷開始,搭配 On-page SEO(像是 Title/Description 優化)、內容配置與網站分類設計,一起佈局。
📌 講者觀點:「內容是主餐,技術是體質。」

講者資訊:https://www.linkedin.com/in/yisan-lee-4bb69b160/
2️⃣ 案例二:JavaScript 渲染而成網站的 SEO 怎麼救?
講者指出,高達 98.9% 的網站都使用 JavaScript,而 JavaScript 網站主要可分為兩類:
- 只是裝飾用途(如 WordPress、Shopify)
- 以 JavaScript 為主要核心生成內容(如 React、Vue.js)
他分享一個慘烈案例 :原本是靜態頁面,後來改為全 JS 渲染,結果 SEO 成效直接崩盤,因為爬蟲根本看不到主要內容。如果你的高品質網頁始終無法被收錄,極有可能與 JS 渲染有關。
如何檢查你的網站是否被 JavaScript 拖累?有三個自我檢查的方式:
- 用瀏覽器的 View Page Source (檢查原始碼)看看主要內容是否存在
- 用 Google Search Console 網址審查工具 & 索引報表
- 若出現 「已檢索 – 目前尚未建立索引」、「轉址式 404 錯誤」就需注意!
常見 JavaScript 問題還包含:
- 用 JS 動態產生 meta tag
- robots.txt 阻擋 CSS/JS
- 連結結構由 JS 動態生成
- sitemap 太久沒更新
- 沒有 HTML 格式的 canonical
📌 重點:JS 本身不是問題,問題在「你怎麼用」。

講者資訊:https://www.linkedin.com/in/wasin-mekkit?fromQR=1
3️⃣ 案例三:一場 JavaScript SEO 災難的逆轉啟示
講者 Loki Yan 分享一個經典案例:他經手一個用 Angular 架構的網站,因渲染後的內容無法被 Googlebot 正常擷取,導致網站流量接近掛零。
他如何拯救這個網站?解決過程包括使用開發者工具、Google Search Console、Screaming Frog 等工具查出問題,並進行一連串優化:
- 簡化 JavaScript 結構
- 移除沒用的 API 呼叫
- 延遲載入非必要 JS
- 將檔案分流、打包重整
成果:從幾乎沒有點擊到一年後達到 80 萬,兩年後更突破 2400 萬點擊。
📌 精彩金句:「你要學會 JS,然後就知道怎麼向工程師提問(challenge)。」

講者資訊: Xinyuan (Loki) Yan
什麼是 Google 友善的 JavaScript?(11:10)
Googlebot 究竟能不能「看懂」你用 JavaScript 建立的內容?
答案是:能看懂,但有條件。講者逐一點出幾個常見問題,這些都是讓 Googlebot「看不到你內容」的元兇
🚫 JS SEO 常見踩雷清單:
- 內容沒出現在渲染後的 HTML 中:Googlebot 雖然會渲染,但如果你用 JS 載入的內容根本沒顯示在 DOM 裡,它還是抓不到。
- Googlebot 無法呼叫 JS:像是某些 API 要登入、設定權限,Googlebot 就會吃閉門羹。
- JS 的執行條件寫太複雜:觸發內容出現的 JS 被設計得太深、執行順序不穩,也會導致「抓不到」。
- 使用者互動才會顯示內容:像是要點擊「展開更多」才出現的內容,Googlebot 不會點擊!這類資訊幾乎不會被讀取到,Googlebot 只會讀取前 10,000px 的內容。
- URL 使用 # hash 導向不同內容:例如 /#products,這種 hash 並不會傳送新的請求給伺服器,爬蟲就看不到內容。
- SPA 架構造成的 Soft 404 問題:單頁應用(SPA)如果內容有問題,HTTP 狀態碼卻沒反應錯誤,Googlebot 會誤判成 Soft 404。

Google 眼中的「頁面內容」是怎麼被理解的?(11:30)
這場的主題回到基本功:Google 到底怎麼判讀你的網頁內容?
講者提醒大家,Google 會根據頁面區塊來評估資訊的重要性,並不是整頁一視同仁!以下是他們對不同區塊的「重視程度」
- Header(頁首)👉 重要度低
- Nav(導覽列)👉 重要度低
- Main Content(主內容)👉 最重要!
也就是說,如果你把原本在 footer 的分類連結、或低轉換的 tag 頁面硬放進主內容區塊,Google 會以為那是你最重要的資訊,反而可能傷到網站整體內容權重。
延伸閱讀:搜尋品質評分者指南
Soft 404 是什麼?什麼狀況會被判定?
這段也提到一個大家常見卻搞不清的問題:「為什麼 Google 判定我的頁面是 Soft 404?」Soft 404 並不是實際 404(錯誤頁),而是「你頁面看起來有問題,但狀態碼卻沒回報錯誤」。原因可能有:
- 網頁內容太少,像是只有幾句話或空空如也
- CMS 或主機錯誤,導致無法載入資料
- JavaScript 為主的網站沒成功渲染內容
- Google 本身判斷錯誤(可能是 bug)
📌 小提醒:如果你發現好好的頁面被標記為 Soft 404,記得打開 Google Search Console 索引報表,對照看看是內容品質、技術錯誤還是渲染問題!
接下來就接午餐時間了~ 吃飽喝足後,下午重點轉向「重複內容」與國際化挑戰!第一場直攻 SEO 的老問題:重複內容該怎麼處理?
如何處理網站重複內容?(12:45)
先釐清一個觀念:重複內容 ≠ 抄襲內容,而是 Google 無法判斷哪一頁才該被納入索引與排名。
重複內容的辨識流程:
- 先辨認 是否為實際重複內容(同樣主題/段落/區塊)
- 再挑選 標準網址(Canonical URL)讓搜尋引擎知道「誰是標準頁面」
多語系網站也要小心!語言相近、內容架構類似的多國版本,若未加上 Hreflang 標記,也可能被視為重複內容,導致 Google 隨機只收錄其中一頁。講者整理出 Google 最常依賴的「信號」來判定哪些內容該被索引:
- 使用者體驗信號:使用者是否真的需要這兩份相似內容?
- 網站技術信號:是否有設置正確的 301 轉址、Canonical、Sitemap?
- 語言與地區信號:是否有加上 hreflang 標記來清楚區分語系?
📌 建議操作方式:
- 使用 301 轉址明確導向主頁
- 確保 HTTPS 狀態碼正確無誤
- 正確設置 <link rel=”canonical”>
- 多語系頁面使用 Hreflang 對應不同地區與語言
- 提供一致且清楚的「標準化信號」,避免讓 Google 猜來猜去
⚡Lightning Session J:網站搬遷不是搬家而已,搞錯方式 SEO 全掛!(12:57)
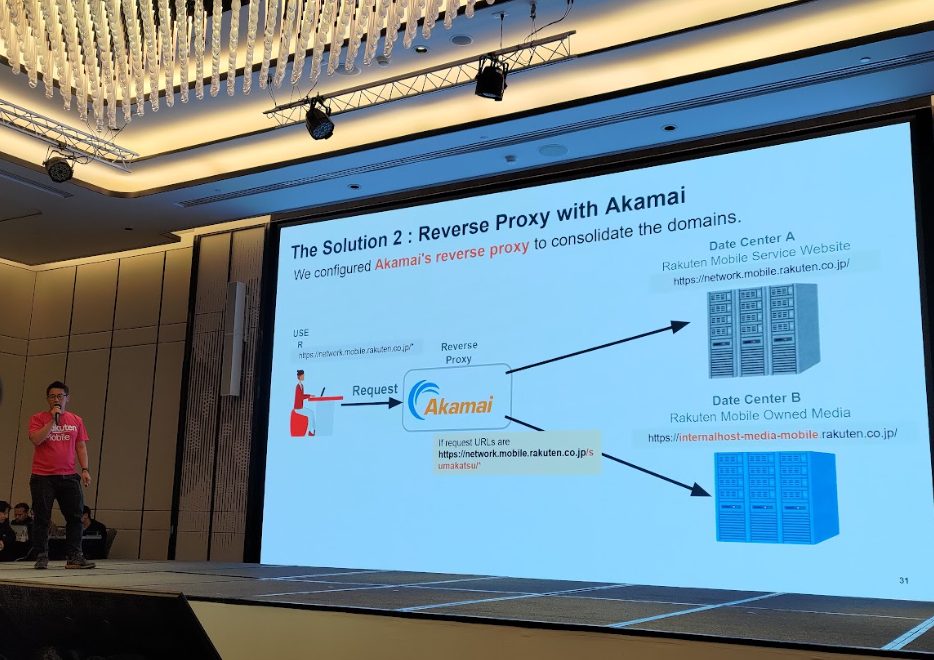
這場由日本樂天技術 SEO 負責人分享他們經歷的一場「搬站升級」,內容毫不閃避實戰難題!他們在網站搬遷時遇到幾個挑戰:
- 301 轉址清單混亂,一開始沒處理好,導致大量頁面連結失效與流量流失
- 搬站過程需透過 Akamai Reverse Proxy (反向代理服務) 處理導流,確保使用者體驗不中斷
透過 Akamai 的反向代理技術,整合兩個不同來源的網站資料。遷移後成效驚人!直接達成「9 倍流量成長」的優化成效!
講者建議重點:內容若掛在主站(主服務網域)下的表現,通常會優於獨立的子網域。
講者資訊:https://www.linkedin.com/in/akihiro-miyata-36158791/
結構化資料是什麼?為什麼它會是搜尋的黃金訊號?(13:05)
Gary 在這場段落一開頭就強調:「結構化資料,就是讓我們更快找到你頁面『金塊』的方式。」
不論是商品、文章、影片還是圖片,只要透過 Google 支援的結構化資料 標記,就能幫助搜尋引擎快速理解頁面重點。尤其在 AI 搜尋與多媒體內容越來越重要的時代,這些標記幾乎成了被擷取的「先決條件」。
講者也提醒,Media Indexing(媒體內容的索引)其實與 HTML 索引是不同步處理的流程,結構化資料在這裡就扮演橋樑角色:讓 Google 更清楚知道「這是什麼」、「要怎麼呈現」、「值不值得讓它曝光」。簡單來說,結構化資料就像是在告訴 Google:「這篇文章有精采影片」「這張圖片是產品主圖」「這段文字是評論摘要」,越清晰、越正確,越有機會出現在更吸睛的位置。
官方參考文件:結構化資料通用指南

媒體內容怎麼做 SEO?透過圖片與影片吸引使用者(13:17~13:27)
接下來這一段聚焦在圖片與影片的索引,圖片與影片常常被當成「裝飾」,但其實它們早就是搜尋結果中的重要內容,能不能被抓到、怎麼呈現,都會影響到 SEO 表現!
圖片該怎麼做才有機會被抓到?
Google 會透過 <img> 標籤的 src、alt、title 及 <picture> 標籤來理解圖片內容:
- alt 是最重要的欄位,請務必寫得具有描述性。
- title 屬於弱信號,但仍可提供額外脈絡。
但須注意,透過 CSS 設定的背景圖片(background-image)不會被搜尋引擎收錄。
另外結構化資料中也能加入圖片,像是文章主圖、商品圖、人物大頭貼(ProfilePage)等,但必須是與頁面內容強相關的主要圖像,才有意義,如果有許多無意義背景圖,還可以考慮阻擋爬取來節省檢索預算。
Q. 那麼應該要阻擋 AI 生成的圖片嗎?
A. 「看你要不要。」Google 的回應很實際,只要有人會搜尋它、而且內容不錯,它就有可能被顯示在搜尋結果,但仍要小心幻覺或錯誤資訊的風險。
Q. 影片怎麼提升搜尋曝光?
A. 影片已經不只出現在 YouTube 裡了,搜尋結果、影片搜尋結果、Discover 都可能露出,Google 也正在擴大支援 key moments、預覽縮圖等豐富功能。
想提升影片的搜尋曝光,有 5 個重要動作:
- 頁面內容本身要夠好(不要只塞影片沒內文)
- 影片嵌入位置要對,最好放在主內容區
- 加上影片結構化資料(JSON-LD 格式最推薦)
- 提供影片 sitemap,幫助搜尋引擎了解內容
- 確認手機與桌機都能正常播放,避免嵌入失敗
同樣的,AI 生成的影片要不要 disallow?
Google 回應一樣是:「看你。」但再度提醒,務必注意內容品質與準確性,尤其是避免 AI 幻覺!

多語系網站怎麼做?國際化與在地化 SEO 策略重點(13:45)
談到國際 SEO,今天這場的關鍵字就是:hreflang + 在地化訊號。只要你的網站有不同語言版本、跨國市場,那這些設定絕對不能忽略!
hreflang 怎麼設才正確?
hreflang 用來告訴 Google:這個頁面有對應的語言/地區版本,請依照使用者所在位置正確導向。最常見的作法,是在 HTML 標籤中加上 <link rel=”alternate” hreflang=”xx-YY”>,或使用 sitemap 告訴 Google 對應關係。
📌 最常見的錯誤:
- A 頁面設定了 hreflang 指向 B,但 B 沒有回指向 A → 失敗
- 使用了錯誤的語言代碼(❌ jp、UK ➜ ✅ ja、GB)
- 只設定地區沒有語言(❌ hreflang=”sg” ➜ ✅ hreflang=”en-sg”)
正確的 hreflang 設定應該是雙向互通,語言+地區都要寫對。
Google 怎麼判斷哪個版本給哪個地區看?
除了 hreflang,Google 也會綜合以下訊號判斷使用者該看到哪個版本的網頁:
- ccTLD(如 .tw、.jp、.uk)
- 伺服器地理位置
- 網站上的其他在地化線索:使用語言、結帳幣別、地區限定連結、企業資訊檔案等
至於用機器翻譯的多語系頁面可以嗎?
Google 的回應是:要看翻譯品質。
若翻出來的內容不符合當地用語、語氣怪怪的、不符文化習慣,就不會是一個好的體驗,也可能無法達到 SEO 效果。

⚡Lightning Session D:GSC、Trends 實戰!國際化 SEO 怎麼做(14:00)
延續前一段的多國語系,這場閃電講座進一步帶來兩個工具的活用技巧:Google Search Console(GSC)與 Google Trends。
1️⃣ Google Search Console 多語系管理術
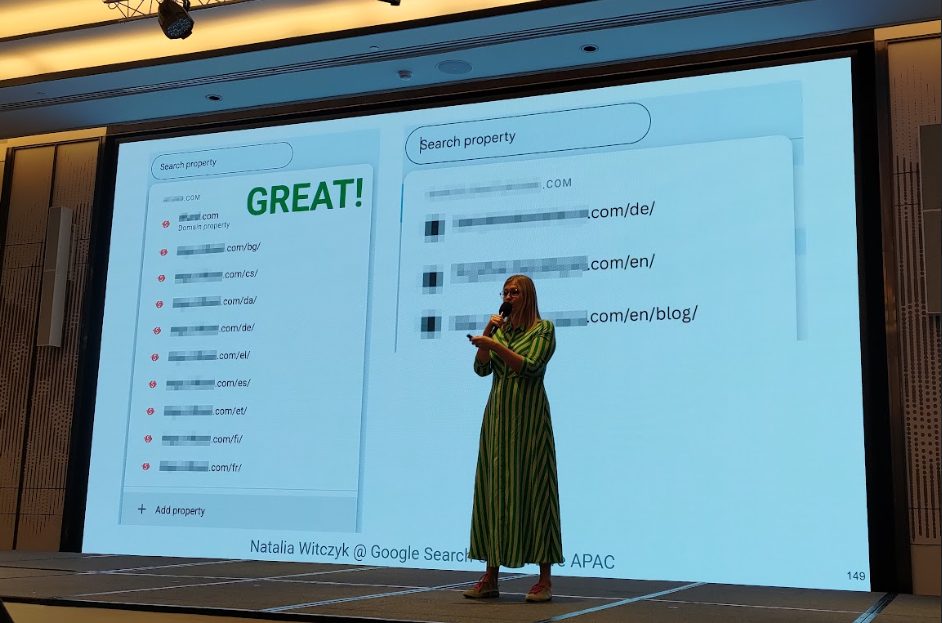
講者強調,如果你有經營多語言、多地區的網站,應該使用「網址資源」而不是「網域資源」來加入 GSC,才能獲得最完整的資料追蹤與優化彈性,就算只是使用子目錄(像是 /en-au/、/en-in/)也 OK!
現場展示的案例圖中,可以看到將每個語言區塊都獨立加入 Google Search Console 追蹤,這樣每個語系就能擁有獨立的資料報表,搭配 API 與爬蟲工具(如 Screaming Frog),可以做更精細的優化分析。
講者資訊:https://es.linkedin.com/in/nataliawitczyk
2️⃣ Google Trends 多語詞觀察法
第二位講者則分享他們如何利用 Google Trends 搭配多語系關鍵字進行趨勢觀察,並提出幾項實用建議,希望 Google 能未來改善:
- 在 Google Trends 中加入 Discover 數據
- 可以像 X.com 一樣查看全球整合趨勢
- 能依「語言」分類而非僅是國家
- 提供更多搜尋量數據與 API 支援
是對 Google 最真誠的許願清單,也呼應了許多 SEO 專家的心聲!

海報發表 E:索引 × 多語系實戰(14:18)
休息時間前,安排了特別的 Poster Session(海報發表),這也是 Google 首度在 Search Central Live 嘗試這種交流方式。與會者可以自由走動,和各主題講者近距離互動、提問、交換意見,特別適合像「索引」、「多語系優化」這種需要因地制宜、case by case 需要靈活討論的議題。分享的主題包含:
- 如何在五分鐘內完成網站健檢
- 多語系 SEO 實戰分享(來自日本、韓國、波蘭的經驗)
例如,來自 LOANDO 團隊的講者,現場分享了如何將波蘭的財經平台成功拓展至羅馬尼亞、烏克蘭、捷克等新市場。從初期遭遇流量下滑的挑戰,到藉由多語系優化策略,包含在地化內容策略、公關操作提升品牌能見度、遵循當地法規政策等方式,進而強化多語系 SEO 成效,最終實現流量與營收的成長。

而另一位針對跨境電商的講者則從語言使用出發,帶來不同的見解:
他分享,當美國產品進入日本市場時,不只是文化適應問題,更要處理一個非常實際的挑戰:商品名稱怎麼翻才對?以「T-shirt」為例,在美國是單一詞彙,但在日本卻可能被搜尋為「圓領 T 恤」、「短袖 T 恤」、「棉質 T 恤」使用者的搜尋方法非常多樣。
為了解日本使用者的真實搜尋習慣,講者不只做市調、分析不同年齡層的用字,甚至連模擬鍵盤輸入方式都納入考量!最後他們打造出一套以機器學習為基礎的「商品名稱翻譯模型」,能在規模化上架商品時,自動轉換為最貼近日本使用者習慣的搜尋字詞,不只優化了頁面 title,還讓國際商家能以最合適的商品翻譯名稱,出現在當地用戶的眼前。

這場互動式的發表形式,不只是聽講,更讓整場活動多了份「國際 SEO 同樂會」的氛圍~
哪些才是真正的「索引信號」?Google 來解答!(15:05)
「你覺得哪些是 Google 用來判斷索引的信號呢?」Gary Illyes 也來一波互動小遊戲,讓大家猜猜哪些訊號會影響索引。結果不少人都選錯,因為像是「Domain Age」「XML Sitemap」「E-E-A-T」其實都不是索引信號!
✅ 是索引信號的有:
- 國家 Country
- 語言
- HTTPS / 安全網站
- Core Web Vitals
- Dofollow 連結
- 內容新鮮度(Recency)
- 垃圾內容違規(Spam Policies Violations)
❌ 不是索引信號的有:
- 網域年齡與歷史
- 結構化資料
- XML Sitemap
- 可爬行性(Crawlability)
- 內容深度與完整性
- 合理的內部連結(Logical Internal Linking)
- 內容可讀性(Readability)
- 主題權威性(Topical Authority)
- 搜尋意圖對齊(Matching Search Intent)
- 關鍵字使用(Keyword in HTML)
- E-E-A-T(專業性、權威性、可信度)
- hreflang 標籤
- Link Velocity(連結成長速度)

這張表就是官方現場直接揭露的版本,有沒有顛覆你的想像?
再次強調一件事:很多我們熟知的 SEO 技術,未必跟「是否被索引」直接相關,尤其像 hreflang、E-E-A-T 或結構化資料,雖然重要,卻是用來提升理解或排序,而不是讓你被「抓進資料庫」的關鍵。
用這個環節提醒大家:搞懂 Google 的排序邏輯很重要,但別忘了先搞懂「被收錄」的基礎機制。
哪些內容能被收進 Google 索引?這些「信號」你要懂!(15:25~15:45)
進入索引機制的「黑盒子」環節。Gary Illyes 直接揭露:不是所有被爬的頁面都會被索引,Google 會挑!想進索引庫?內容必須夠「實用、可信」,也就是大家熟知的高品質內容。
🚫 不被索引的常見原因:
- 頁面設了 noindex
- 網站內部標註為過期內容(expired)
- soft 404 錯誤
- 重複內容
- 垃圾內容或違反政策(至於是哪些政策?Gary 神秘地說「這是秘密😏」)
📌 有兩種常見的 GSC 狀態,別急著修它:
- Discovered – currently not indexed(已找到,目前尚未建立索引):已發現頁面,但暫時不檢索,是因為當下檢索會讓你網站過載,之後會再來。
- Crawled – currently not indexed(已檢索 – 目前尚未建立索引):已經爬了,但目前沒打算收進資料庫。這種情況,不用硬改,先觀察就好!
那我們在索引報表中看到的錯誤到底要不要處理?
Gary 的建議很清楚:「不一定!有些只是暫時狀態,並不是問題本身。」Google 搜尋團隊也再次推薦,如果你想更理解整個索引判斷邏輯,可以回頭翻翻這兩份官方文件:詳盡指南:Google 搜尋的運作方式、檢索及索引相關主題總覽
Google Trends API 登場!用資料看懂搜尋趨勢(15:50)
今天最後一場,以一場充滿驚喜的小遊戲收尾,現場觀眾現學現用 Google Trends 介面,搶答「在過去五年內,YouTube 上 Pad Thai (泰式炒河粉) 的第二熱搜相關話題是?」等趣味題目!
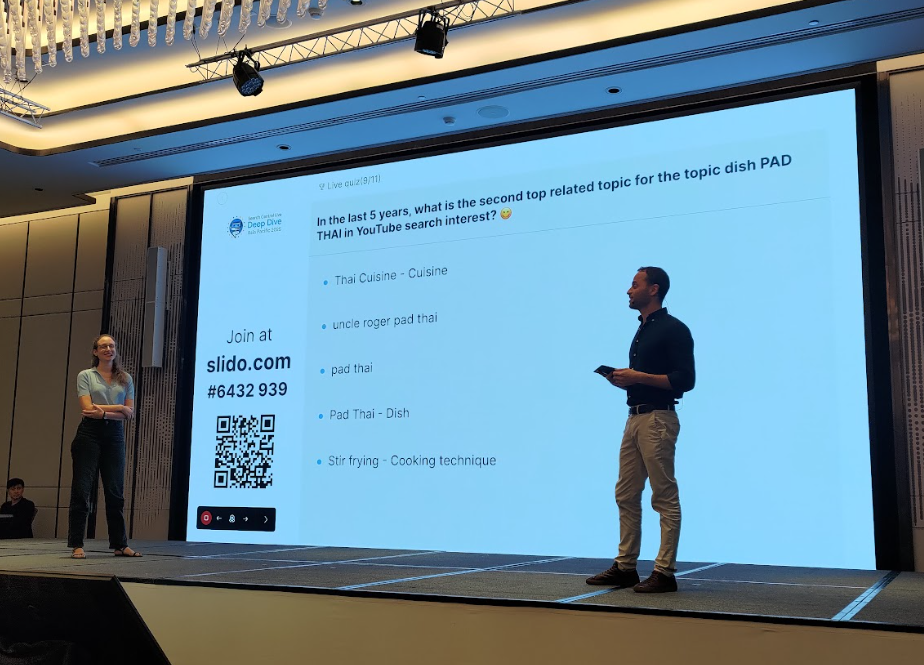
雖然是遊戲,但也讓大家實際體會 Google Trends 的強大功能:它不只可以看單一關鍵字,還能比對主題、掌握用戶搜尋意圖,甚至辨識地區與時間趨勢,從網站、圖片、新聞、購物到 YouTube 全部支援。
Trending now 功能更強大!
- 即時顯示趨勢變化(4/24/48 小時、7 天)
- 提供搜尋斷點、搜量、分類
- 有新聞連結 + SERP 畫面,幫你快速掌握流量方向
想搶節慶流量?一定要提早 1~2 個月布局!
重磅亮點來了:Google Trends API 正式開放試用申請!
台下立刻爆出歡呼聲,因為這是很多 SEO 團隊、內容團隊、數據工程師等待已久的功能!Google Trends API 可以做到:
- 擷取 scaled data(不再是相對值 0~100,而是保留絕對比例)
- 時間範圍從 近 48 小時到過去 5 年都能查
- 可自由選擇 日、週、月、年顯示
- 支援 國家 / 類別篩選
- 讓你一次查出「香蕉 vs 蘋果」誰搜量高,不會因為查的組合不同而重置圖表數據!(之前以相對值 呈現,所以圖表數據會變)
如果你有固定追蹤趨勢需求,強烈建議盡早申請試用,這將是內容與 SEO 佈局的超級助攻!

❓QA時間問答精華
最後壓軸照例是開放提問時間。今天的提問同樣精彩,從 Gemini、Trends API 到索引邏輯,全都問到點上。以下是現場整理的 10 個值得筆記的精華問答:
Q1. Gemini 上的搜尋也有被計入 Google Trends 嗎?
A1. 還沒有。
Q2. Google Trends API 有包含 Trending Now 功能嗎?
A2. 沒有,目前尚未支援。
Q3. 謠言有提到 ChatGPT 使用 Google 的索引資料?是真的嗎?
A3. 講者表示不知道、不在乎、不回應謠言 XD
Q4. SSR(Server-side Rendering)相比動態渲染(CSR)有優勢嗎?
A4. 沒有直接優勢,但 CSR 網站在索引時比較容易出現問題。
Q5. Google 如何判定並處理 soft 404?會使用先前爬取的內容嗎?
A5. 不會。被判定為 soft 404 的頁面可能會被取消索引,舊內容不會被拿來替代。
Q6. Google Trends 中 search terms 跟 topics 有什麼差別?
A6. search terms 是具體搜尋詞,topics 是概念主題,會自動包進錯字等變形,但無法看到精確用詞。
Q7. 結構化資料對 SEO 有幫助,是指那些能顯示 Rich Result 的結構化資料嗎?
A7. 結構化資料不影響排名,有幫助但難以具體量化。
Q8. 針對 “crawled-not indexed” (已檢索 – 尚未建立索引)的頁面,該怎麼辦?
A8. 通常代表這些頁面內容品質不夠好或有技術問題。要向 Googlebot 證明你的內容「值得索引」。sitemap 雖然有助於被發現與爬取,但對實際進入索引幫助有限。
Q9. 為什麼 Google Webcache 被移除了?未來會有替代工具嗎?
A9. 沒有說原因,但猜測是「使用率低」、「營運成本高」。目前也沒有推出類似替代方案的計畫。
Q10. 像菲律賓這樣的多語種國家,該怎麼做語言優化?
A10. 像菲律賓或印度這種國家,多語系使用者比例平均,目前真的沒有完美解法。Google :「等未來有統一的語言再說吧!」
awoo 的觀察與反思
從今天的內容可以發現:「SEO 的技術底層,依然值得深入投資。」
不論是 JavaScript 網站的渲染挑戰、多語系 hreflang 的錯誤處理,還是索引判定與資源配置,其實每個看似細節的地方,都有可能對網站收錄與排名造成實質影響。
Gary Illyes 在台上的提醒很中肯:「你不需要為了 AI 而重新命名 SEO。」但也正因如此,更需要回到 SEO 的核心技術,確保網站的內容能被「看見」、被「理解」、也被「正確地放進搜尋結果」。
這也是 awoo 團隊參與活動的初衷:持續吸收第一線的技術趨勢與演進思維,轉化為對品牌真正有幫助的策略與建議。
🔗 查看其他篇
◀️ 前一天主題:【Search Central Live Deep Dive】Day1:SEO is Dead?AI 搜尋時代的 SEO 新解讀!|awoo 活動實記
結語
Search Central Live Deep Dive 為期三天,不只是資訊密集的研討會,更是與全球搜尋專家交流的平台。awoo 將持續追蹤相關趨勢與實務應用,協助品牌掌握搜尋優化機會。下一篇是活動第 3 天,主題將聚焦在「搜尋結果的形成邏輯 × Search Console 問題診斷 × 趨勢洞察實戰」,敬請期待!
如有任何網站流量成長相關問題與需求、或想瞭解更多 AI SEO/GEO 服務歡迎填寫表單立即諮詢,將有 awoo 專業顧問與您聯繫。
Contact Us
「*」代表必填欄位


